Twitter API - random tweets generator
Introduction
I am a Twitter user for almost a decade. Every day I spend some time reading tweets from people connected with my hobbies. In this entry, I would like to make a simple ETL pipeline using Twitter API and set it to run once a week. However, it would be so short post with just a pipeline. Luckily I know some NLP and Flask basics. This is enough to make a random tweet generator web app based on tweets from the most popular Formula 1’s journalists. The chosen ones are Andrew Benson, Chris Medland, Adam Cooper, and Edd Straw.
General architecture
This is a graph presenting the general architecture of this mini-project. It might be not perfect but I hope it is clear enough.
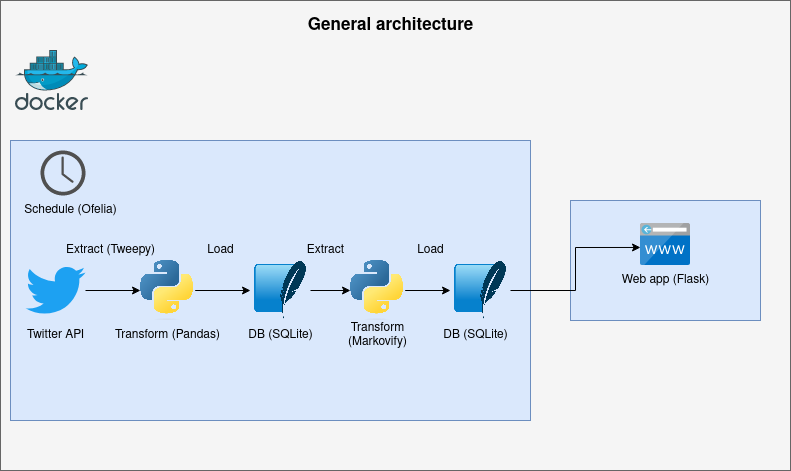
I do not like to over-complicate things. The project is rather simple. It contains just SQLite database and python libraries. Tweepy is a library that makes accessing Twitter API a lot easier. Markovify is an awesome simple Markov chain generator. Of course, there are better methods for text generation like LSTM, GAN, or GPT-2. However, my primary goal is to show the process of creating an ETL pipeline. Displaying a randomly generated tweet is just an addition. It does not need to be accurate, but I can be funny. The ETL script will be simple, so Ofelia (modern replacement for cron in docker environments) is enough to schedule it instead of using a framework like Airflow. Someone could wonder why sentences are not generated instantly within the first transform. The answer is Twitter API has some limitations and it’s not possible to fetch a large number of tweets in no time. I would like to build a large database so the generated tweets should be better every week. Scheduled script and a simple flask app will be containerized via Docker as separated services. The directory and file structure should look like this:
tweets_generator
| .gitignore
| .dockerignore
| .env
| docker-compose.yaml
|___src
| |___etl
| | | requirements.txt
| | | Dockerfile
| | | tweets_etl.py
| | |___utils
| | | __init__.py
| | | config.py
| | | twitter_auth.py
| | | sqlite_connector.py
| |___app
| | | requirements.txt
| | | Dockerfile
| | | app.py
| | |___static
| | | | style.css
| | |___templates
| | | app.html
ETL
Utils
In the utils directory I am going to store config.py with environment variables, sqlite_connector, twitter_auth.py with Twitter API configuration and authentication. In the config files the standard os.environ takes care of environment variables. It will be important to configure them also in docker-compose.yaml, but I am going to show this in the last part of the post. Tweepy makes authenticating with the Twitter API super simple. The connect_sqlite function is useful because I will set up a connection with the database multiple times.
#config
import os
consumer_key = os.environ['CONSUMER_KEY']
consumer_secret = os.environ['CONSUMER_SECRET']
access_token = os.environ['ACCESS_TOKEN']
access_token_secret = os.environ['ACESS_TOKEN_SECRET']
#twitter_auth
import tweepy
from utils.config import consumer_key, consumer_secret,
access_token, access_token_secret
def tweepy_connect():
# twitter api config
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
return tweepy.API(auth)
#sqlite_connector
import sqlite3
def connect_sqlite():
return sqlite3.connect('/code/db/tweets_db.db')
Get user’s tweets
This is the crucial part of the entire ETL process. Without original tweets, it is impossible to generate funny random ones. The tweepy’s user_timeline method is the right tool to acquire the user’s tweets. It returns the list of objects, I need just the username, the id of the tweet, and the text. It is convenient to save them as a pandas data frame. I would also like to have no duplicates in the database. My solution is to query the maximum id of the tweet for the user and set the since_id parameter in the user_timeline method to that value. The since_id is None only if the process is running the first time (database is empty).
def get_user_tweets(username: str, count: int) -> pd.DataFrame:
try:
# set connection with database
conn = connect_sqlite()
cur = conn.cursor()
# get maximum id from tweets_table
cur.execute(
'SELECT MAX(id) FROM tweets_table WHERE name = ?', (username,))
# save query result
since_id = cur.fetchone()[0]
conn.close()
except:
since_id = None
# set connection with twitter api via tweepy
api = tweepy_connect()
# get the last count of tweets from the user's timeline with id higher than max id in database
tweets = api.user_timeline(screen_name=username,
count=count, include_rts=False, tweet_mode='extended', since_id=since_id)
# save tweets to pandas dataframe
df = pd.DataFrame(data=[(tweet.id, tweet.full_text, username)
for tweet in tweets], columns=['id', 'tweets', 'name'])
return df
Preprocess tweets
The posts in social medias are full of urls, hashtags (#), mentions (@) or mistakes like double spaces. It is good idea to get rid of them before modeling. It can be done using simple regex with pandas replace method. It is possible to have an empty tweets after removing hashtags, mentions and urls so there is a need to drop them also.
def preprocess_tweets(df: pd.DataFrame) -> pd.DataFrame:
# remove hashtags and mentions
df.tweets = df.tweets.replace("(@|#)[A-Za-z0-9_]+", "", regex=True)
# remove urls
df.tweets = df.tweets.replace(r"(http\S+|www.\S+)", "", regex=True)
# remove multiple spaces
df.tweets = df.tweets.replace(r"\s+", ' ', regex=True)
# remove empty rows
df.tweets = df.tweets.replace('', np.nan)
df = df.dropna(axis=0, subset=['tweets'])
return df
Load tweets
This is a simple step - the data frame created before just needs to be appended to the table in the database using pandas to_sql method. In case of initial load, the table should be created before with the id as primary key.
def load_tweets(df: pd.DataFrame) -> None:
# set connection with database
conn = connect_sqlite()
cur = conn.cursor()
# create table (if not exists) with tweets, name and id as primary key
cur.execute(
'CREATE TABLE IF NOT EXISTS tweets_table (id INT, tweets TEXT, name TEXT, CONSTRAINT primary_key_constraint PRIMARY KEY (id))')
# append dataframe to the existing table
df.to_sql('tweets_table', conn, if_exists='append', index=False)
conn.commit()
conn.close()
Markovify tweets
This step includes extracting data and transforming in one function. Pandas read_sql method allows to query the table and save results to the data frame instantly. The markovify.NewlineText class is a good chose to build a model using data frame. Tweets have maximum length of 280 characters so restricting generated sentences also is a proper idea.
def markovify_tweets() -> pd.DataFrame:
# set connection with database
conn = connect_sqlite()
# load tweets to dataframe
df = pd.read_sql('SELECT tweets FROM tweets_table', conn)
conn.close()
# make a markov model
model = markovify.NewlineText(df.tweets)
# save 100 markovified sentences to dataframe
df = pd.DataFrame((model.make_short_sentence(280)
for x in range(100)), columns=['sentence'])
return df
Load markovified tweets
This step is pretty similar to the first load. The main difference here is replacing the existing table instead of appending.
def load_markovified_tweets(df: pd.DataFrame) -> None:
# set connection with database
conn = connect_sqlite()
cur = conn.cursor()
# create table if not exists
cur.execute(
'CREATE TABLE IF NOT EXISTS markovified_tweets_table(sentence TEXT)')
# replace existing table
df.to_sql('markovified_tweets_table', conn,
if_exists='replace', index=False)
conn.commit()
conn.close()
Run
Every part of the ETL is already created. The get_user_tweets function must be invoked for every journalist separately. Pandas concat in a mix with simple mapping a list of journalists do the job here.
def run() -> None:
# run whole etl process
journalists = ['andrewbensonf1', 'ChrisMedlandF1',
'adamcooperf1', 'eddstrawf1']
# get tweets from every listed user and concat them
df = pd.concat(map(lambda x: get_user_tweets(
x, 200), journalists), ignore_index=True)
df = preprocess_tweets(df)
load_tweets(df)
df = markovify_tweets()
load_markovified_tweets(df)
if __name__ == '__main__':
run()
Dockerfile
In the Dockerfile for the ETL script, I just need to build a python environment. Commands to be executed by scheduler will be specified in the docker-compose so no cmd or entrypoint here.
FROM python:3.9-slim
WORKDIR /code
COPY . .
RUN pip install -r requirements.txt
App
Considering the simplicity of the app I won’t show the HTML or CSS files here.
Flask
The python code is not so complicated, because the app just shows random tweets from the database. The random tweet is selected from the table using ORDER BY RANDOM(). I know it is not so efficient way, but the table has only 100 rows so I suppose I can use it here.
import sqlite3
from flask import Flask, render_template
app = Flask(__name__)
@app.route('/')
def get_tweet():
# connect database
conn = sqlite3.connect('/code/db/tweets_db.db')
cur = conn.cursor()
# select random entry
cur.execute(
'SELECT sentence FROM markovified_tweets_table ORDER BY RANDOM() LIMIT 1')
tweet = cur.fetchone()[0]
conn.close()
return render_template('app.html', tweet=tweet)
if __name__ == '__main__':
app.run(host="0.0.0.0", port=5000)
Dockerfile
Dockerfile contains building a python environment and running the app with a specified host and port.
FROM python:3.9-slim
WORKDIR /app
COPY . .
RUN pip install -r requirements.txt
CMD python app.py 0.0.0.0:5000
Compose
The docker-compose is a tool for defining and running multi-container Docker applications. The first service defined is the tweets_etl. The image is built from the Dockerfile previously created. The environment variables are defined in the .env file. To let the compose automatically find them it is required to use ${variable} or $variable syntax. The first shell command - python tweets_etl.py is used to run the python script initially. It is important because the scheduler will be set to run weekly, I do not want to wait a week for the first run. The second one tail -f /dev/null keeps the container alive. The tweet-etl and the app images share the volume. In the labels, Ofelia scheduler is configured to run the specified command with specified environment variables weekly. The second service is the Ofelia. It depends on the tweets_etl service, so it will wait until the service has been started. For the app service built from the previously created Dockerfile ports must be specified.
version: '3'
services:
tweets-etl:
build:
context: ./src/etl
dockerfile: Dockerfile
environment:
CONSUMER_KEY: ${CONSUMER_KEY}
CONSUMER_SECRET: ${CONSUMER_SECRET}
ACCESS_TOKEN: ${ACCESS_TOKEN}
ACCESS_TOKEN_SECRET: ${ACCESS_TOKEN_SECRET}
command: >
sh -c " python tweets_etl.py && tail -f /dev/null"
volumes:
- ${VOLUME}
labels:
ofelia.enabled: "true"
ofelia.job-exec.tweets-etl.schedule: "@weekly"
ofelia.job-exec.tweets-etl.command: "python tweets_etl.py"
ofelia.job-exec.tweets-etl.environment: '["CONSUMER_KEY=${CONSUMER_KEY}",
"CONSUMER_SECRET=${CONSUMER_SECRET}",
"ACCESS_TOKEN=${ACCESS_TOKEN}", "ACCESS_TOKEN_SECRET=${ACCESS_TOKEN_SECRET}"]'
ofelia:
image: mcuadros/ofelia:latest
restart: always
depends_on:
- tweets-etl
command: daemon --docker
volumes:
- /var/run/docker.sock:/var/run/docker.sock:ro
app:
build:
context: ./src/app
dockerfile: Dockerfile
container_name: flask
ports:
- "5000:5000"
volumes:
- ${VOLUME}
Now the whole infrastructure can be built and started using docker-compose up -d from the directory with docker-compose.yaml and .env. The site should be accesible at http://localhost:5000/.

The tweets mostly don’t make sense, but the code works fine. It is also probably not safe to run it in the production environment!
Conclusion
I hope the project is at least not bad because I am just starting with a more complicated usage of Docker. I also know that nowadays ETL tasks are usually scheduled in a framework like Airflow or Luigi in the cloud platforms with a few clicks but I just wanted to have it on my infrastructure. Nevertheless, I will probably use more advanced schedulers in future posts. Wish me luck!