Fairy Tail database - scraping MyAnimeList
Introduction
Web scraping is not the most gentle method to obtain data. However, if the site does not provide any API and scraping is not disallowed, it might be the only option. The ability to scrape the data, turn it into a readable format and insert it into the database is nice to have then. I am going to scrape pieces of information about Fairy Tail from MyAnimeList. It is the biggest anime and manga community on the internet. Why just Fairy Tail? It is one of my favorite ones and is big enough to build a database and maybe create tiny but interesting exploratory data analysis in the future.
General architecture
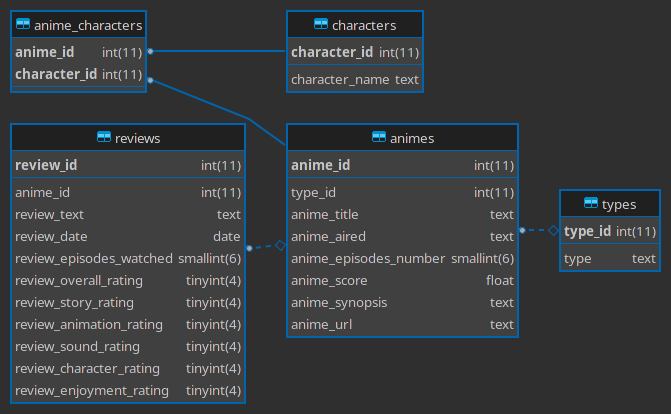
For scraping the website I will use mainly requests and BeautifulSoup with a little regex help. To structurize the scraped data I will use pandas. The chosen RDBMS is MariaDB, the open-source fork of MySQL. I would like to have the following schema:
 The process of web scraping should contain:
The process of web scraping should contain:
- checking if scraping the website is not disallowed,
- planning and building the database,
- exploring the raw HTML,
- parsing the HTML using BeautifulSoup,
- cleaning and structuring obtained data using Pandas,
- delaying the requests, setting errors handling and monitoring,
- inserting scraped data into a relational database.
Scraper
Urls
The list of URLs every of Fairy Tail anime is the first thing we need. At the start I create the helper function get_response with predefined header and timeout, because it will be used to scrape every database’s table.
# make a requests with a predefined header and timeout
def get_response(url: str):
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:95.0) Gecko/20100101 Firefox/95.0'}
return requests.get(url, headers=headers, timeout = 10)
To find the URL of every Fairy Tail animation I need to specify the URL with the search parameters, for me, it is ‘q=fairy+tail&cat=anime’, so the full URL will be: https://myanimelist.net/anime.php?q=fairy+tail&cat=anime. The URL of every anime on this page has ‘hoverinfo_trigger fw-b f1-1’ class. It is important to note, that the search shows also the results with one of the keywords (ie just ‘fairy’ or ’tail’’), which are not what I am looking for, so I scrape just the URLs with specified titles in them. Handling timeouts and response status code checking is also implemented and will look the same for every part of the scraper.
# returns list of MAL's urls of Fairy Tail animes based on search results
def get_urls(search_url: str, title: str) -> List:
# handle timeouts
try:
# make a requests to a web page
response = get_response(search_url)
except requests.exceptions.Timeout:
print(f'{search_url}: timeout')
pass
# check if suceeded
if response.status_code != 200:
print(f'{search_url}, response status code: {response.status_code}')
pass
# parse raw html with BeautifulSoup
soup = bs(response.text, 'html.parser')
# create list of urls with Fairy Tail in them
urls = ([x['href'] for x in soup.find_all(
'a', class_='hoverinfo_trigger fw-b fl-l') if title in x['href']])
print('Urls scraped successfully')
return urls
Animes
Scraping the basic info about anime from its main page on MAL is the very first step. Pieces of information like title, score or synopsis are well tagged and easy to obtain. The type, air dates, and episodes number are tagged with the same div and span classes. Luckily the hundreds of code challenges solved on the Codewars gave me some confidence in using classic regex so I can use it here to obtain the required data. It is good to create a helper function for this because I will use it for other tables also.
def regex_search_between(text: str, expression1: str, expression2: str) -> str:
try:
# helper function for finding string between two strings
return re.search(rf'{expression1}(.*?){expression2}', text).group(1).strip()
except:
raise Exception('Nothing found!')
There are probably other methods to scrap those pieces of information, but finding a string between two specified expressions is suitable here for me. Next, scraped data is appended to the data frame. There is also a need to make anime title and type categorical and generate the ids columns (primary and foreign keys) using cat.codes. The anime_type column will be dropped after creating the types table. The animes which are not yet aired have no numeric episodes numbers and scores, so I have to get rid of them by replacing them with NaN values. For every scraping task with a loop involved, I am going to inject a 3 seconds sleep time between each iteration. It is generally good practice to do not overwhelm the resources of the server or just not get banned.
# returns animes dataframe
def get_animes(urls: List) -> pd.DataFrame:
# init dataframe
df_animes = pd.DataFrame()
for x in urls:
# handle timeouts
try:
# make a requests
response = get_response(x)
except requests.exceptions.Timeout:
print(f'{x}: timeout')
pass
# check if suceeded
if response.status_code != 200:
print(f'{x}, response status code: {response.status_code}')
pass
soup = bs(response.text, 'html.parser')
# get title
anime_title = soup.find(
'h1', class_='title-name h1_bold_none').get_text()
# create a string with the informations about anime for further searching with classic regex
informations = ''.join(
[x.get_text() for x in soup.find_all('div', class_='spaceit_pad')])
# get type
anime_type = regex_search_between(informations, 'Type:\n', '\n')
# get episodes number
anime_episodes_number = regex_search_between(
informations, 'Episodes:\n', '\n')
# get aired dates
anime_aired = regex_search_between(informations, 'Aired:\n', '\n')
# get score
anime_score = soup.find('span', class_='score-label').get_text()
# get synopis
anime_synopsis = soup.find('p', itemprop='description').get_text()
# get url
anime_url = x
# append all data to dataframe
df_animes = df_animes.append({'anime_title': anime_title, 'anime_type': anime_type,
'anime_aired': anime_aired, 'anime_episodes_number': anime_episodes_number,
'anime_score': anime_score, 'anime_synopsis': anime_synopsis, 'anime_url': anime_url}, ignore_index=True)
print(f'{x} scraped successfully')
# sleep for 5 sec
time.sleep(3)
# make the anime title categorical and create type_id column
df_animes['anime_title'] = df_animes['anime_title'].astype('category')
df_animes['anime_id'] = df_animes['anime_title'].cat.codes
# make the anime type categorical and create type_id column
df_animes['anime_type'] = df_animes['anime_type'].astype('category')
df_animes['type_id'] = df_animes['anime_type'].cat.codes
# get rid of 'unknown' and 'N/A'
df_animes['anime_episodes_number'] = df_animes['anime_episodes_number'].replace(
'Unknown', np.nan)
df_animes['anime_score'] = df_animes['anime_score'].replace('N/A', np.nan)
return df_animes
Types
The types table is the easy one, it just requires copying type_id and anime_type colums from animes table and droping duplicates. Now I can also drop the anime_type column from animes table.
# returns types dataframe
def get_types(df: pd.DataFrame) -> pd.DataFrame:
df_types = df[['type_id', 'anime_type']].drop_duplicates().rename(columns={
'anime_type': 'type'})
return df_types
# returns animes dataframe without anime_type columns
def drop_types(df: pd.DataFrame) -> pd.DataFrame:
df_animes = df.drop(columns=['anime_type'])
return df_animes
Characters
Due to the many-to-many relationship between characters and animes tables, the join table animes_characters with foreign keys anime_id and character_id shall be created also. To scrap character names I need to add ‘/characters’ at the end of each anime’s URL. Character names are well tagged, so it is not so hard to find them all, append them to the data frame, and create characters ids.
# returns animes_characters dataframe
def get_animes_characters(df: pd.DataFrame) -> pd.DataFrame:
# init empty dataframe
df_animes_characters = pd.DataFrame()
# loop over urls and ids from animes table
for x, y in zip(df['anime_url'], df['anime_id']):
# get characters page url
url = x + '/characters'
# handle timeouts
try:
# make a request
response = get_response(url)
except requests.exceptions.Timeout:
print(f'{url}: timeout')
pass
# check if suceeded
if response.status_code != 200:
print(f'{url}, response status code: {response.status_code}')
pass
soup = bs(response.text, 'html.parser')
# find all character names
character_names = soup.find_all('h3', class_='h3_character_name')
# append each character name and anime id to the dataframe
for z in character_names:
name = z.get_text()
df_animes_characters = df_animes_characters.append(
{'anime_id': y, 'character_name': name}, ignore_index=True)
print(f'{url} scraped successfully')
# sleep for 5 sec
time.sleep(3)
# make the character name categorical and create character_id column
df_animes_characters['character_name'] = df_animes_characters['character_name'].astype(
'category')
df_animes_characters['character_id'] = df_animes_characters['character_name'].cat.codes
return df_animes_characters
Now I can create the characters table and drop the characters names from the join table in the same way like for the types table.
# returns characters dataframe
def get_characters(df: pd.DataFrame) -> pd.DataFrame:
df_characters = df[['character_id', 'character_name']].drop_duplicates()
return df_characters
# returns animes_characters dataframe without character_name column
def drop_names(df: pd.DataFrame) -> pd.DataFrame:
df_animes_characters = df.drop(columns=['character_name'])
return df_animes_characters
Reviews
Scraping the reviews is a bit more tricky. Site with reviews has pagination, every of animes has a different number of reviews. In my case, the most are 23 pages for the first Fairy Tail series, so I need to loop over 23 pages. If anime does not have that many pages, it is just blank so there is nothing to scrape. Fields like review_text, rieview_overall_rating, review_story_rating, review_animation_rating, review_sound_rating, review_character_rating, review_enjoment_rating are in one div of review block. Ratings can be easily scraped using the regex_search_between function I created before. However the whole text needs to have removed random empty lines and spaces, so creating another helper function preprocess_review_text is not a bad idea.
def preprocess_review_text(text: str) -> str:
try:
# remove empty lines and random spaces from the string, split the string to scores and review text
scores = "\n".join([x.strip()
for x in text.splitlines() if x.strip()][:12]) + ' '
review_text = "\n".join([x.strip()
for x in text.splitlines() if x.strip()][12:-2])
# get overall rating
overall_rating = regex_search_between(scores, 'Overall\n', '\n')
# get story rating
story_rating = regex_search_between(scores, 'Story\n', '\n')
# get animation rating
animation_rating = regex_search_between(scores, 'Animation\n', '\n')
# get sound rating
sound_rating = regex_search_between(scores, 'Sound\n', '\n')
# get character rating
character_rating = regex_search_between(scores, 'Character\n', '\n')
# get enjoyment rating
enjoyment_rating = regex_search_between(scores, 'Enjoyment\n', ' ')
return review_text, overall_rating, story_rating, animation_rating, sound_rating, character_rating, enjoyment_rating
except:
raise Exception('Nothing to preprocess')
The function returns a tuple with ratings and review text. The review_date and review_episodes_watched can be obtained from the other div which I call the right_corner. The primary key review_id is created directly from the index.
# returns reviews dataframe
def get_reviews(df: pd.DataFrame) -> pd.DataFrame:
df_reviews = pd.DataFrame()
for x, y in zip(df['anime_url'], df['anime_id']):
for z in range(1, 24):
url = x + f'/reviews&p={z}'
# handle timeouts
try:
# make a request
response = get_response(url)
except requests.exceptions.Timeout:
print(f'{url}: timeout')
pass
# check if suceeded
if response.status_code != 200:
print(f'{url}, response status code: {response.status_code}')
pass
soup = bs(response.text, 'html.parser')
review_blocks = soup.find_all('div', class_='borderDark')
for block in review_blocks:
# separate the area with review text
review = block.find(
'div', class_='spaceit textReadability word-break pt8 mt8').get_text()
# extract text and ratings from review text
review_text = preprocess_review_text(review)[0]
review_overall_rating = preprocess_review_text(review)[1]
review_story_rating = preprocess_review_text(review)[2]
review_animation_rating = preprocess_review_text(review)[3]
review_sound_rating = preprocess_review_text(review)[4]
review_character_rating = preprocess_review_text(review)[5]
review_enjoyment_rating = preprocess_review_text(review)[6]
# separate the right corner of the review block and create a list without random new lines and spaces
right_corner = block.find('div', class_='mb8').get_text()
right_corner = [x.strip()
for x in right_corner.splitlines() if x.strip()]
# extract review date and episodes watched from the right corner
review_date = datetime.strptime(
right_corner[0], '%b %d, %Y').date()
review_episodes_watched = right_corner[1]
review_episodes_watched = regex_search_between(
review_episodes_watched, '', ' of')
#review_episodes_watched = block.find('div', class_='lightLink spaceit').get_text()
# get anime id
anime_id = y
# append all data to dataframe
df_reviews = df_reviews.append({'anime_id': anime_id, 'review_date': review_date,
'review_episodes_watched': review_episodes_watched, 'review_text': review_text,
'review_overall_rating': review_overall_rating, 'review_story_rating': review_story_rating,
'review_animation_rating': review_animation_rating, 'review_sound_rating': review_sound_rating,
'review_character_rating': review_character_rating, 'review_enjoyment_rating': review_enjoyment_rating}, ignore_index=True)
print(f'{url} scraped successfully')
# sleep for 5 sec
time.sleep(3)
# create review_id column from an index
df_reviews = df_reviews.reset_index().rename(
{'index': 'review_id'}, axis=1)
# get rid of 'unknown' values
df_reviews['review_episodes_watched'] = df_reviews['review_episodes_watched'].replace('Unknown', np.nan)
return df_reviews
Database
Let’s start with creating the database with tables running the following script from MariaDB’s interactive client:
source /path/create_tables.sql
/*create_tables.sql*/
CREATE DATABASE IF NOT EXISTS ft_db;
USE ft_db;
CREATE TABLE IF NOT EXISTS animes(
anime_id INT NOT NULL,
type_id INT NOT NULL,
anime_title TEXT,
anime_aired TEXT,
anime_episodes_number SMALLINT,
anime_score FLOAT,
anime_synopsis TEXT,
anime_url TEXT,
CONSTRAINT animes_pk PRIMARY KEY (anime_id)
);
CREATE TABLE IF NOT EXISTS types(
type_id INT NOT NULL,
type TEXT,
CONSTRAINT types_pk PRIMARY KEY (type_id)
);
CREATE TABLE IF NOT EXISTS characters(
character_id INT NOT NULL,
character_name TEXT,
CONSTRAINT characters_pk PRIMARY KEY (character_id)
);
CREATE TABLE IF NOT EXISTS animes_characters(
anime_id INT NOT NULL,
character_id INT NOT NULL,
CONSTRAINT animes_characters_pk PRIMARY KEY(anime_id, character_id)
);
CREATE TABLE IF NOT EXISTS reviews(
review_id INT NOT NULL,
anime_id INT NOT NULL,
review_text TEXT,
review_date DATE,
review_episodes_watched SMALLINT,
review_overall_rating TINYINT,
review_story_rating TINYINT,
review_animation_rating TINYINT,
review_sound_rating TINYINT,
review_character_rating TINYINT,
review_enjoyment_rating TINYINT,
CONSTRAINT reviews_pk PRIMARY KEY(review_id)
);
Now I can connect to the database using SQLAlchemy. It is quite important, becuase pandas to_mysql method supports SQLAlchemy’s engines, otherwise treats everything like SQLite. Every of pandas dataframes scraped previously can be appended to the specified table in a loop, with the error handling.
# create sqlalchemy eninge
engine = create_engine(
f'mysql+pymysql://{username}:{password}@{host}/ft_db')
# set connection with db
conn = engine.connect()
# tables in db
tables = ['animes', 'types', 'characters', 'animes_characters', 'reviews']
# dfs
dfs = [df_animes, df_types, df_characters,
df_animes_characters, df_reviews]
# append dataframes to the tables with error handling
for df, table in zip(dfs, tables):
try:
df.to_sql(table, conn, if_exists='append', index=False)
except ValueError as vx:
print(vx)
except Exception as ex:
print(ex)
else:
print(f'{table} inserted successfully')
# close connection with db
conn.close()
After running the scraper -python scraper.py, the tables are full of data. Let’s also run another SQL script to add the foreign keys.
/*create_relations.sql*/
USE ft_db;
ALTER TABLE animes
ADD CONSTRAINT animes_type_fk FOREIGN KEY (type_id) REFERENCES types(type_id);
ALTER TABLE animes_characters
ADD CONSTRAINT animes_characters_anime_fk FOREIGN KEY (anime_id) REFERENCES animes(anime_id),
ADD CONSTRAINT animes_characters_character_fk FOREIGN KEY (character_id) REFERENCES characters(character_id);
ALTER TABLE reviews
ADD CONSTRAINT reviews_anime_fk FOREIGN KEY (anime_id) REFERENCES animes(anime_id);
The database schema is identical to the ER Diagram from the ‘General architecture’ part of the post now.
Conclusion
The MyAnimeList is a relatively easy website to scrape. It is a very well-structured site, so scraping requires just basic BeautifoulSoup methods or regex. To make the scrapping process more professional tests and logging could be added. Scrapping the websites is an interesting task, it requires basic web dev knowledge also. However, I prefer to obtain the data using traditional APIs, without the risk to get banned or overwhelming someone’s servers. I would like to make more projects using the data from MyAnimeList in the future. Wish me luck!