Sentiment Analysis - Reddit's feelings about a new League champion
Introduction
Releases of the new champions in League of Legends are usually quite controversial. The players are often unhappy because the new champion is unbalanced or just bugged. Three days ago Renata came into the game. I would like to check what people think about her by conducting a sentiment analysis of Reddit’s posts with comments. Sentiment analysis is a procedure that detects the polarity (for example: positive, negative, or neutral) within the text. Analyzing the sentiment of words from the post will help me determine if the community is happy about the new champion or not. It is the overview of the process for this analysis:
- Get the data from Reddit API
- Preprocess the data
- Apply the sentiment analyzer
- Interpret and visualize the results
The NLP is probably my favorite area of data science, but to be honest I do not expect that the results will be scientifically valuable. I am creating this study because I am just curious and to show the process.
Obtain the data
The PRAW - The Python Reddit API Wrapper is a very helpful library to obtain the data. To be honest it makes the whole process easy-peasy.
The first thing to do is set the connection with the Reddit API.
from typing import Dict, List
import emoji
import nltk
import pandas as pd
import praw
import seaborn as sns
from matplotlib import pyplot as plt
from praw.models import MoreComments
from wordcloud import WordCloud
nltk.download('omw-1.4')
nltk.downloader.download('vader_lexicon')
nltk.download('wordnet')
nltk.download('stopwords')
from nltk.corpus import stopwords
from nltk.sentiment.vader import SentimentIntensityAnalyzer
from nltk.stem import WordNetLemmatizer
from nltk.tokenize import RegexpTokenizer
plt.style.use("dark_background")
plt.rcParams["figure.figsize"] = (10, 5)
reddit = praw.Reddit(client_id = 'id', client_secret = 'secret', user_agent = 'user_agent')
Now I can get the post ids and titles. I am interested in the posts with the most activity, so it is reasonable to set sorting to ‘hot’ in the search query. The function returns a dictionary with ids and titles of posts with a specified keyword from the subreddit. The ids will be useful to obtain the comments in the next step. The titles will be analyzed with the comments. The subreddit I am querying is a ’leagueoflegends’ and the keyword is ‘Renata’. I decided to obtain top 50 posts. I think it will be enough data to analyze.
# Get post titles and their ID that contains certain keyword, from subreddit, sorted by hot. Return dict with id: headline.
def get_titles(subreddit: str, count: int, keyword: str) -> Dict:
d = {submission.id:submission.title for submission in reddit.subreddit(subreddit).search(keyword, sort='hot', limit=count)}
return d
d = get_titles('leagueoflegends', 50, 'renata')
ids = list(d.keys())
headlines = list(d.values())
Obtaining the comments is also not so hard. The only trick here is the replace_more method, which replaces or removes the MoreComments object from the comments forest, so the exception telling that MoreComments has no attribute ‘body’ can be avoided.
# Get comments from posts. Return a pandas dataframe.
def scrap_comments(ids: List) -> List:
comments = []
for x in ids:
post = reddit.submission(id=x)
post.comments.replace_more(limit=None)
for comment in post.comments.list():
comments.append(comment.body)
return comments
comments = scrap_comments(ids)
x = comments + headlines # concat lists
Preprocess the data
On the internet forums posts usually do not contain only text. They can have links, emojis, images, etc. A lot of words that people use are also not worth analyzing. They are called ‘stop words. These are the most common words in any language (like articles, prepositions, pronouns, conjunctions, etc) and do not add much information to the text. It is good to get rid of all those before doing the analysis. I also need to join all of the strings from the list into one, with the comma separator (it is required by both libraries used here), tokenize the string, and lemmatize the tokens. Tokenization is a way of separating a piece of text into smaller units called tokens - in my case the tokens are just lowercase words. Lemmatization is a technique that is used to reduce words to a normalized form - root words. The main library to preprocess the texts I use is Natural Language Toolkit - a Swiss Army knife for NLP.
# Convert list to string separated by comma, lowercase, remove urls, punctation, tokenize, remove stopwords, lemmatize.
def preprocess_text(txt: List) -> List:
txt = ', '.join(x.lower() for x in txt) # join all the strings sep by comma
txt = emoji.get_emoji_regexp().sub(u'', txt) # get rid of emoji
tokenizer = RegexpTokenizer('\w+|\$[\d.]+|http\S+') # tokenize
txt = tokenizer.tokenize(txt)
print(f'With stopwords: {len(txt)}')
stop_words = set(stopwords.words('english')) # set up the english stopwords
txt_no_stop_words = [x for x in txt if x not in stop_words] # get rid of stopwords
print(f'Without stopwords: {len(txt_no_stop_words)}')
txt_no_stop_words = ([WordNetLemmatizer().lemmatize(x) for x in txt_no_stop_words]) # lemmatize
return txt_no_stop_words
words = preprocess_text(x)
With stopwords: 62949
Without stopwords: 32445
It is worth noticing that removing stop words reduced the number of words by almost a half. The last thing I have to do is remove the ‘riot’ word from the list. It could be classified as a negative, but it is the name of the League of Legends developer.
words = [x for x in words if x != 'riot']
Apply the sentiment analyzer
Now it is time to find the polarity for each token. The model I will use is VADER - Valance Aware Dictionary for Sentiment Reasoning. VADER sentimental analysis relies on a dictionary that maps lexical features to emotion intensities known as sentiment scores. The score values are between -1 and 1, where -1 means the most negative and 1 means the most positive. The zero means neutral, but I will also use the typical threshold values and classify the word as neutral when it has a score between -0.05 and 0.05. The function will create a list of key-value pairs with a word and a score, then transform it into a data frame and label the results.
def sentiment_analyze(words: List) -> pd.DataFrame:
model = SentimentIntensityAnalyzer() # initiate the analyzer
scores = []
for word in words: # loop over the words and calculate a score for every
polarity = model.polarity_scores(word)
polarity['words'] = word
scores.append(polarity)
df = pd.DataFrame.from_records(scores) # create a dataframe from list of dicts
df['label'] = 'Neutral' # label based on a score
df.loc[df['compound'] > 0.05, 'label'] = 'Positive'
df.loc[df['compound'] < -0.05, 'label'] = 'Negative'
return df
df = sentiment_analyze(words)
Results
It looks like the model works and the data frame is well prepared, so I can check the results now. Let’s start with counting labels.
df_counts = df['label'].value_counts()
plt.pie(df_counts, labels=df_counts.index, shadow=True, explode=(0.1, 0.1, 0.1), autopct='%1.2f%%', colors=['orange', 'green', 'violet'])
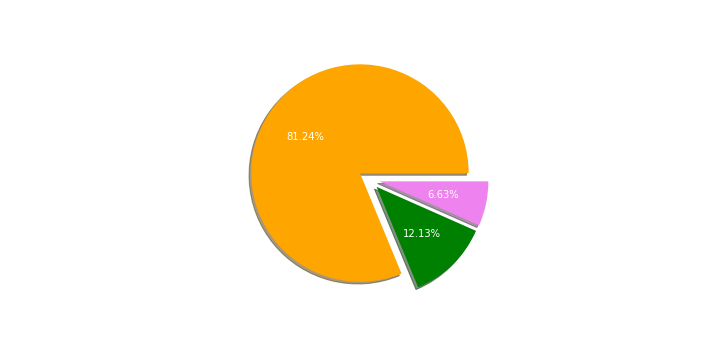
Most of the words are neutral. However, there are almost 2 times more positive skewed words. It is quite a stupefying result for me because my expectation was a huge negative connotation of the Reddit posts.
Let’s also take a look at the top 15 most common negative and positive words.
p_words = df.loc[df['label'] == 'Positive']['words']
p_words = nltk.FreqDist(p_words).most_common(15)
p_words
[('like', 437),
('champion', 193),
('champ', 188),
('play', 129),
('good', 129),
('pretty', 108),
('ability', 106),
('better', 94),
('well', 89),
('want', 82),
('lol', 80),
('support', 77),
('revive', 72),
('yeah', 70),
('great', 56)]
n_words = df.loc[df['label'] == 'Negative']['words']
n_words = nltk.FreqDist(n_words).most_common(15)
n_words
[('damage', 95),
('kill', 88),
('enemy', 79),
('bad', 75),
('attack', 56),
('miss', 51),
('hard', 50),
('fight', 49),
('shit', 43),
('weird', 35),
('die', 35),
('fuck', 31),
('low', 31),
('hate', 28),
('worse', 27)]
Looking at the negative words, I guess some of the typical gameplay words could be removed from the tokens list in future games related sentiment analyses. A lot of games have a combat system, so I think the typical negative words might be not negative in the context of a computer game.
It is also nice to create word clouds with the top words.
wordcloud_positive = WordCloud(mode = "RGBA", background_color=None, width=3000, height=2000).generate(' , '.join(str(x) for x in p_words))
plt.imshow(wordcloud_positive)
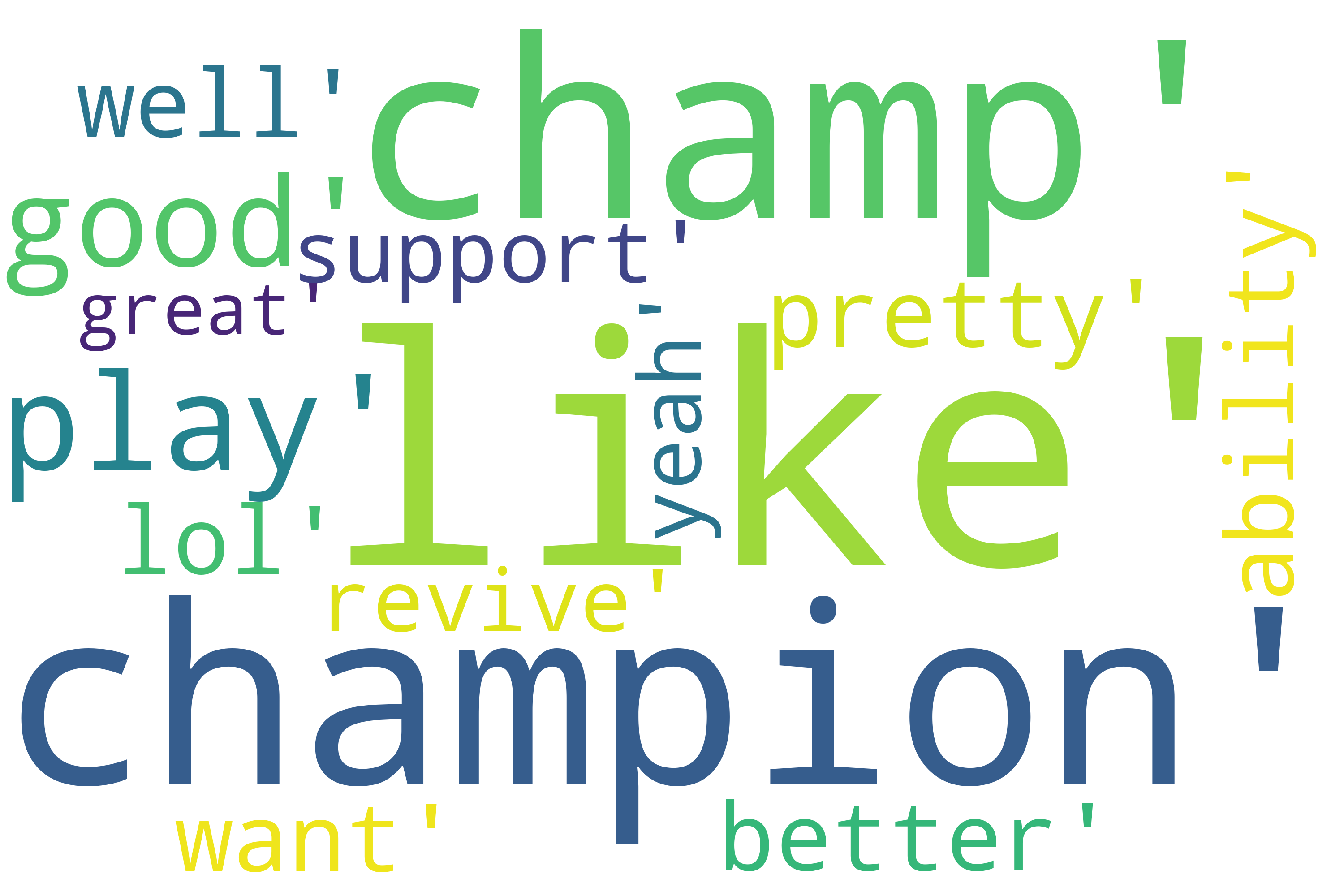
wordcloud_negative = WordCloud(mode = "RGBA", background_color=None, width=3000, height=2000).generate(' , '.join(str(x) for x in n_words))
plt.imshow(wordcloud_negative)
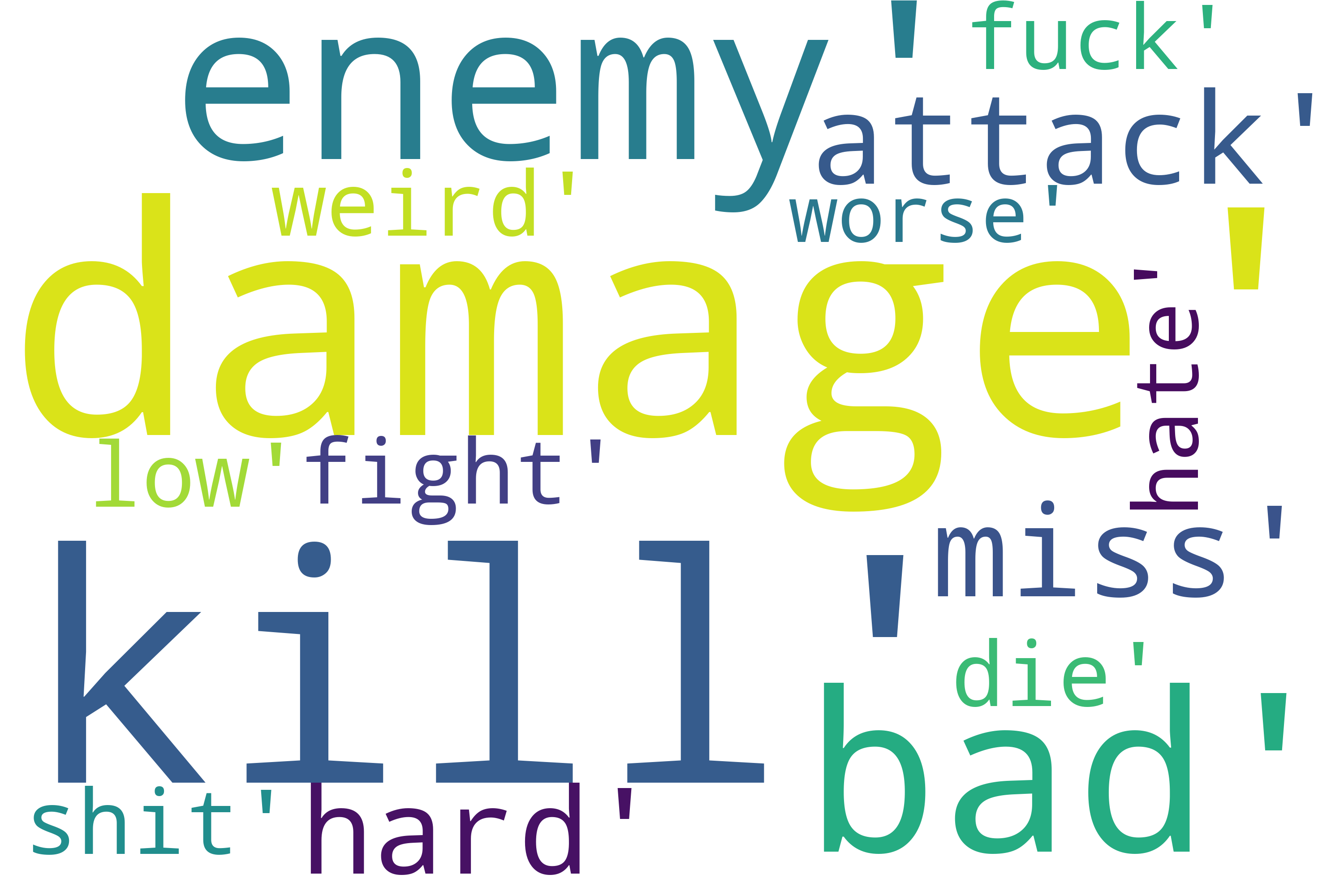
Conclusion
The short sentiment analysis of Reddit posts about the new champion in League of Legends shocked me a bit. I was almost sure that most people are negative, at least before the hotfixes or patch. 12.13% of around 32 thousand analyzed words were positive, just 6.63% were negative. I think that is a huge difference. I do not see more valuable insights from the study. I guess NLP in the world of League of Legends would be more interesting if it could be possible to analyze the messages from the in-game chat. I think I could be more than 90% of negatives 😀. I hope the study was at least not boring, even if it does not have any strong findings. Cya in the next post!
References
- https://blog.bitext.com/what-is-sentiment-analysis-and-how-does-it-work
- https://towardsdatascience.com/sentimental-analysis-using-vader-a3415fef7664
- https://towardsdatascience.com/text-pre-processing-stop-words-removal-using-different-libraries-f20bac19929a
- https://www.analyticsvidhya.com/blog/2020/05/what-is-tokenization-nlp/
- https://levelup.gitconnected.com/reddit-sentiment-analysis-with-python-c13062b862f6
- https://towardsdatascience.com/step-by-step-twitter-sentiment-analysis-in-python-d6f650ade58d
- https://towardsdatascience.com/twitter-sentiment-analysis-in-python-1bafebe0b566