Last FM API - building ELT pipeline with dbt
Introduction
Almost all of my data engineering mini projects contained a standard ETL pipeline. However, nowadays the ELT approach has advantages also. In the ELT process, the raw data is loaded directly into the target system and converted there. The benefits of the ELT design might be for example shorter development time, quicker loading, less knowledge or technology stack requirements. Of course, it depends on the complexity of the project or pipeline. More complicated cases usually use the mix of ETL & ELT approaches. The tool I would like to learn is the dbt. It is the development framework that combines modular SQL with software engineering best practices to make data transformation reliable, fast, and fun. In this post, I will obtain the data about the music I listen to from the Last FM API, load it into the Postgres database, and use dbt to transform the data. It is a pure learning post and my first usage of the dbt, so probably boring, but I hope not.
General architecture
This is an illustrative graph presenting the overview of the ELT pipeline:
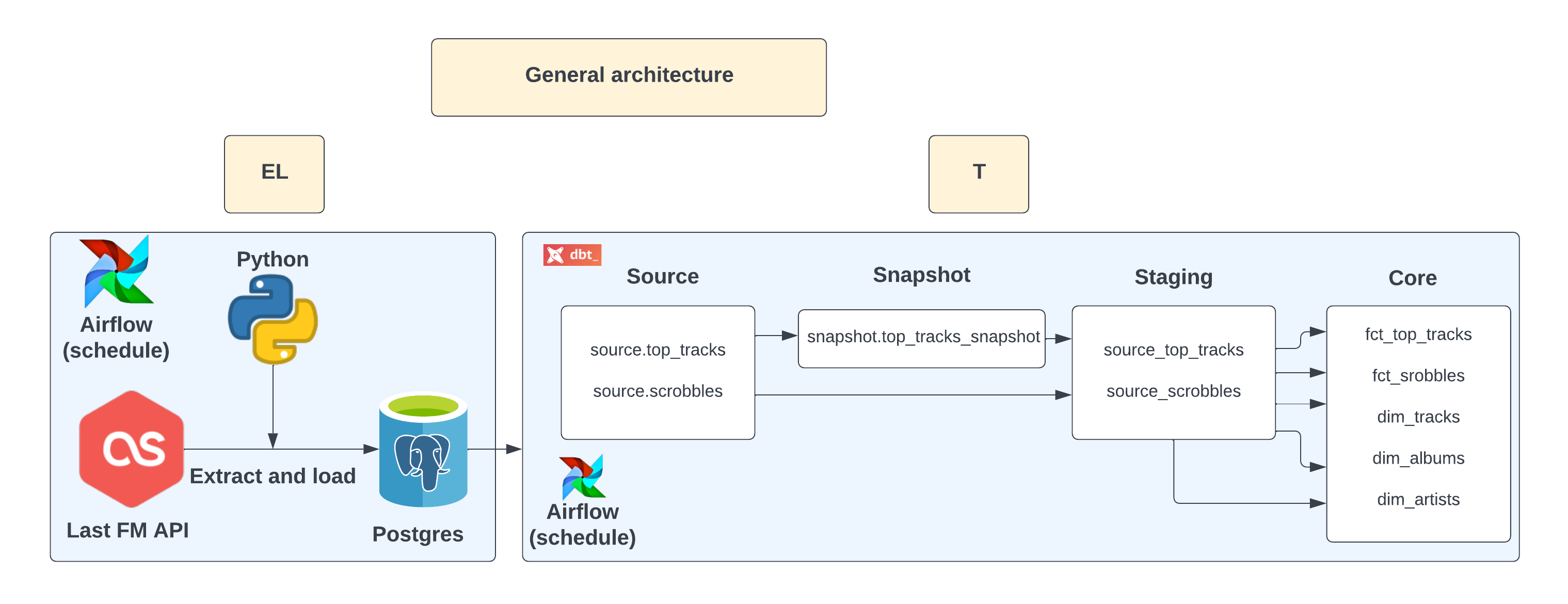 Extract and load part will be done using python and scheduled to run once a week using Airflow. Loaded raw data will be transformed into a handy data warehouse following all the best practices like testing, staging tables, or snapshots using slowly changing dimensions type 2.
Extract and load part will be done using python and scheduled to run once a week using Airflow. Loaded raw data will be transformed into a handy data warehouse following all the best practices like testing, staging tables, or snapshots using slowly changing dimensions type 2.
Extract Load
The EL part of the process is just a python script. One function will scrape my scrobbles and save them to the database’s table. The second one will make the with the 50 top tracks from my whole listening history.
Scrobbles
The first thing to do is set up the connection with Last FM API and a Postgres database. The pyLast is a really helpful tool for operating with the Last FM API. I will create two helper functions because the connections will be set multiple times in the code.
# connect with the postgres database
def connect_db(dbname: str, user: str, password: str, host: str) -> psycopg.Connection:
return psycopg.connect(dbname=dbname, user=user, password=password, host=host)
# connect with the last fm api
def connect_lastfm_api(api_key: str, api_secret: str, username: str) -> pylast.LastFMNetwork:
return pylast.LastFMNetwork(api_key=api_key, api_secret=api_secret, username=username)
To obtain my scrobbles I need to specify two timestamps: from (beginning timestamp of a range - only display scrobbles after this time) and to (end timestamp of a range - only display scrobbles before this time). The first one is just the maximum timestamp from the table. In the case of the initial load, it will be the start of the day 365 days ago. I know it is quite long, but I would like to have a full data set and it will be just around 8k records in my case. The second date is the start of the current date (I mean 00:00).
def get_song_plays(username: str, apikey: str, apisecret: str, dbname: str, dbuser: str, dbpassword: str, host: str) -> None:
# initiate the api
network = connect_lastfm_api(apikey, apisecret, username)
# connect with the database
conn = connect_db(dbname, dbuser, dbpassword, host)
cur = conn.cursor()
# get timestamp of the start of current date
today = datetime.utcnow().date()
today_start = datetime(today.year, today.month,
today.day, tzinfo=tz.tzutc())
today_start_timestamp = int(datetime.timestamp(today_start))
# get the max date from a database or a 365 days ago - only for the initial load
try:
cur.execute(
'SELECT MAX(playback_timestamp) FROM music_schema.scrobbles')
# add 1 to do not scrape the track with the max timestamp again
from_date_timestamp = cur.fetchone()[0] + 1
except:
from_date = today - timedelta(days=365)
from_date = datetime(
from_date.year, from_date.month, from_date.day, tzinfo=tz.tzutc())
from_date_timestamp = int(datetime.timestamp(from_date))
The get_recent_tracks method is the correct one to quickly obtain the scrobbles. It gives a list from the newest to the latest song play. I would like to reverse it and have a design when the highest scrobble_id equals the newest song play. Then a list of dictionaries with information about every listened track is created. The Last FM API doesn’t provide any fields with the unique identifiers of albums, tracks, or artists. The only option is something called ‘mbid’, which is not the best option for polish artists, because of the lack of information in the mbid database. That’s why I need to create provisional ids for albums and tracks. Their names can be the same among various artists so concatenating them probably solves this problem just for this learning post. The distinction of artists with the same name is probably impossible, but luckily I do not listen to any artists with identical ids and it is just a learning mini project so I can leave this problem.
# get the recent tracks from the specified user and between specified dates
recent_tracks = network.get_user(username).get_recent_tracks(
time_from=from_date_timestamp, time_to=today_start_timestamp, limit=None)
# reverse the list
recent_tracks = recent_tracks[::-1]
# initiate empty list
songs = []
# create a dict with informations about every track played
for x in recent_tracks:
try:
song_dict = {}
track = network.get_track(x.track.artist.name, x.track.title)
artist = network.get_artist(x.track.artist.name)
album = (
network.get_album(x.track.artist.name,
x.album) if x.album else x.album
) # sometimes there is no album for a track
song_dict["playback_date"] = x.playback_date
song_dict["playback_timestamp"] = x.timestamp
song_dict["track_title"] = track.get_title()
song_dict["track_duration"] = track.get_duration()
song_dict["track_listener_count"] = track.get_listener_count()
song_dict["album"] = album.get_title() if x.album else "Unknown"
song_dict["album_play_count"] = album.get_playcount(
) if x.album else None
song_dict["album_listener_count"] = (
album.get_listener_count() if x.album else None
)
song_dict["artist"] = artist.get_name()
song_dict["artist_bio_summary"] = artist.get_bio_summary()
song_dict["artist_bio_published_date"] = artist.get_bio_published_date()
song_dict["artist_listener_count"] = artist.get_listener_count()
song_dict["artist_play_count"] = artist.get_playcount()
song_dict["album_id"] = (
song_dict["album"] + "_" + song_dict["artist"] if song_dict['album'] != 'Unknown' else 'Unknown'
) # create provisional album_id
song_dict["track_id"] = (
song_dict["track_title"] + "_" + song_dict["artist"]
) # create provisional track_id
songs.append(song_dict)
except Exception as e:
logging.error(e)
The last thing is loading the data into the database table. It is possible (very low odds) that I do not listen to music in a given period, so handling the exceptions is required.
try:
# get keys of a single dict
columns = songs[0].keys()
# get list of values
values = [[value for value in song.values()] for song in songs]
# create table if not exists - for the initial load
cur.execute(
"""
CREATE TABLE IF NOT EXISTS music_schema.scrobbles (
scrobble_id SERIAL PRIMARY KEY,
playback_date TIMESTAMP,
playback_timestamp INT,
track_title TEXT,
track_duration INTEGER,
track_listener_count INTEGER,
album TEXT,
album_play_count INTEGER,
album_listener_count INTEGER,
artist TEXT,
artist_bio_summary TEXT,
artist_bio_published_date TEXT,
artist_listener_count INTEGER,
artist_play_count INTEGER,
album_id TEXT,
track_id TEXT)
"""
)
# insert the values into a table
cur.executemany(
"""INSERT INTO music_schema.scrobbles({}) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)""".format(
",".join(columns)
),
values,
)
conn.commit()
except Exception as e:
conn.rollback()
# possible no scrobbles in the given period of time
logging.error(e)
# close the connection with database
conn.close()
Top tracks
The start of the process is quite similar to the previous function. The difference here is the usage of the get_top_tracks pylast’s method and a simple counter in a dictionary for creating the ranking field.
def get_top_tracks(username: str, apikey: str, apisecret: str, dbname: str, dbuser: str, dbpassword: str, host: str) -> None:
# connect with the api
network = connect_lastfm_api(apikey, apisecret, username)
# connect with the database
conn = connect_db(dbname, dbuser, dbpassword, host)
cur = conn.cursor()
# the time period over which to retrieve top tracks for
top_tracks = network.get_user(username).get_top_tracks(
limit=50, period="overall"
)
# initiate empty list
top_list = []
# create a dictionary with information about the top tracks
try:
c = 1
for x in top_tracks:
top_dict = {}
top_dict["ranking"] = c
top_dict["artist"] = x.item.get_artist().get_name()
top_dict["track_title"] = x.item.get_title()
top_dict["track_id"] = top_dict["track_title"] + \
"_" + top_dict["artist"]
top_dict["listens_count"] = x.weight
top_list.append(top_dict)
c += 1
except Exception as e:
logging.error(e)
The last step is upserting the data into the database’s table. Upsert means updating the row if it already exists, otherwise inserting a new row. In my case, the inserting option is just important for an initial load. The ranking should always have a constant number of rows. The upsert feature in PostgreSQL is the INSERT ON CONFLICTstatement.
try:
# get keys of a single dict
columns = top_list[0].keys()
# get list of values
values = [[value for value in d.values()] for d in top_list]
# create a table if not exists - for the initial load
cur.execute(
"""
CREATE TABLE IF NOT EXISTS music_schema.top_tracks(
ranking INTEGER UNIQUE,
artist TEXT,
track_title TEXT,
track_id TEXT,
listens_count INT
)"""
)
# upsert values
cur.executemany(
"""INSERT INTO music_schema.top_tracks(ranking, artist, track_title, track_id, listens_count)
VALUES(%s, %s, %s, %s, %s) ON CONFLICT (ranking) DO UPDATE SET
(artist, track_title, track_id, listens_count) =
(EXCLUDED.artist, EXCLUDED.track_title, EXCLUDED.track_id, EXCLUDED.listens_count) """,
values,
)
conn.commit()
except Exception as e:
conn.rollback()
logging.error(e)
# close the connection with database
conn.close()
Transform
Source
Source tables are the tables loaded to the warehouse by the previously created EL process. They can be defined in the handy .yml file. It enables referring to them by using the source function in the later models. Tests can be also added to the models. For testing in the dbt, the user can create the tests or use one of the predefined tests. Dbt has four already defined generic tests: unique, not_null, accepted_values, and relationships. For the source, I need unique and not_null to test the correctness of the primary key. I have just one table with raw data in the warehouse so not a lot of work here.
version: 2
sources:
- name: music_schema
description: data from application database, brought in by an EL process
tables:
- name: scrobbles
columns:
- name: scrobble_id
tests:
- not_null
- unique
- name: top_tracks
columns:
- name: ranking
tests:
- not_null
- unique
Snapshot
Entity’s attributes are sometimes changing. For example, in my case, the top tracks ranking can change. The changes can be captured in the data warehouse. In this post, I will use the SCD2 which is ‘slowly changing dimension type 2’. In this way of storing and modeling the dimensional data, a new row is created for a new value with either a start date/end date or version. Having this feature in my case does not have a lot of sense. But for learning purposes, I will make a snapshot based on a ranking (which is a unique field for a top_tracks table). It will allow me to track the changes in my favorite tracks over time. Creating SCD2 tables in dbt is super easy with the dbt snapshot. Creating a snapshot in dbt requires defining the target database, schema, unique key, strategy, and columns to identify row updates. The check strategy can be used for tables that do not have a column with a timestamp or date for updates. This strategy works by comparing a list of columns between their current and historical values. If any of these columns have changed, then dbt will invalidate the old record and record the new one. If the column values are identical, then dbt will not take any action. If a table has a proper column with a time of update the timestamp strategy is recommended.
{% snapshot top_tracks_snapshot %}
{{
config(
target_database='music_warehouse',
target_schema='snapshots',
unique_key='ranking',
strategy='check',
check_cols=['track_id', 'listens_count']
)
}}
select * from {{ source('music_schema', 'top_tracks') }}
{% endsnapshot %}
Staging
Staging models read raw data from a source or like in my case from the snapshot. This area involves data cleaning and sometimes even joins or other more advanced transformations. My dbt project shall contain 2 staging tables: stg_scrobbles and stg_top_tracks.
The first things to transform in the stg_scrobbles are the ids. I can create a numeric surrogate key for artists using the dense_rank() function. The second thing is the artist_bio_summary field. If bio doesn’t exist on the Last FM, the API returns an ugly URL with HTML tags. regexp_replace() function is really useful for getting rid of that URLs. The last thing is the artist_bio_published_date. This field has a default value of 01-01-1970 when there is no bio. This date is not true so I need to replace it also.
-- stg_scrobbles.sql
with source as (
select *
from {{ source('music_schema', 'scrobbles') }}
),
stg_scrobbles as (
select scrobble_id,
playback_date,
track_title,
track_duration,
track_listener_count,
album as album_title,
album_play_count,
album_listener_count,
artist as artist_name,
-- get rid of html syntax
regexp_replace(artist_bio_summary, '\<a.*?\</a>', 'Unknown') as artist_bio_summary,
case
when artist_bio_published_date = '01 Jan 1970, 00:00' then 'Unknown'
else artist_bio_published_date
end as artist_bio_published_date,
artist_listener_count,
artist_play_count,
album_id,
track_id,
-- create numeric ids
dense_rank() over (
order by artist
) as artist_id
from source
)
select *
from stg_scrobbles
For the stg_top_tracks I don’t need to make any transformations. The only thing worth noting here is that the source is a snapshot table.
-- stg_top_tracks.sql
with source as (
select *
from {{ ref('top_tracks_snapshot') }}
),
stg_top_tracks as (
select ranking,
artist as artist_name,
track_title,
track_id,
listens_count,
dbt_valid_from as valid_from,
dbt_valid_to as valid_to
from source
)
select *
from stg_top_tracks
Marts
Marts are stores of models that describe business entities and processes. To be honest, I can say that marts are just folders with the final products of the transforming process. Usually, they are grouped by business units, for example, marketing or product. My mini-project will have just a core mart. The core directory contains models that are shared across an entire business entity. It defines the fact and dimension models. Models and tests should be documented in a .yml file, as well as in previous steps. Using the test of a relationship for a fact table is a good practice.
version: 2
models:
- name: dim_albums
description: albums dimensions table
columns:
- name: album_id
description: unique id of an album
tests:
- unique
- not_null
- name: album_title
description: title of an album, might be 'Unknown' for a singles etc
- name: album_play_count
description: number of album's plays
- name: album_listener_count
description: number of users who listened to the album
- name: dim_artists
columns:
- name: artist_id
description: unique id of an artist
tests:
- unique
- not_null
- name: artist_name
description: name of an arist
- name: artist_bio_summary
description: description of an artist, can be 'Unknown'
- name: artist_bio_published_date
description: date of publishing artist's bio, can be 'Unknown'
- name: artist_listener_count
description: number of users who listened to the arists
- name: artist_play_count
description: number of artist's plays
- name: dim_tracks
columns:
- name: track_id
description: unique id of a track
tests:
- unique
- not_null
- name: track_title
description: title of a track
- name: track_duration
description: duration of a track
- name: track_listener_count
description: number of track listeners
- name: fct_scrobbles
columns:
- name: scrobble_id
description: unique id of the scrobble
tests:
- not_null
- unique
- name: track_id
description: fk to tracks dim
tests:
- relationships:
to: ref('dim_tracks')
field: track_id
- name: artist_id
description: fk to artists dim
tests:
- relationships:
to: ref('dim_artists')
field: artist_id
- name: album_id
description: fk to albums dim
tests:
- relationships:
to: ref('dim_albums')
field: album_id
- name: fct_top_tracks
columns:
- name: ranking
description: track's ranking
tests:
- not_null
- name: track_id
description: fk to tracks dim
tests:
- relationships:
to: ref('dim_tracks')
field: track_id
- name: artist_id
description: fk to artist dim
tests:
- relationships:
to: ref('dim_artists')
field: artist_id
Creating dimension and fact models is quite simple, it requires just selecting appropriate fields. For the dimensions, I select only the tracks, albums, and artists with the highest scrobble id - with the newest values. Dimension models are analogous, so I don’t think there is a sense to show code for all three.
-- dim_tracks_sql
with staging as (
select *
from {{ ref('stg_scrobbles') }}
),
dim_tracks as (
select distinct stg.track_id,
stg.track_title,
stg.track_duration,
stg.track_listener_count
from staging as stg
inner join (
select max(scrobble_id) as scrobble_id
from staging
group by track_id
) as sub on stg.scrobble_id = sub.scrobble_id
)
select *
from dim_tracks
-- fct_scrobbles.sql
with staging as (
select *
from {{ ref('stg_scrobbles') }}
),
fct_scrobbles as (
select scrobble_id,
playback_date,
artist_id,
track_id,
album_id
from staging
)
select *
from fct_scrobbles
-- fct_top_tracks.sql
with staging as (
select *
from {{ ref('stg_top_tracks') }}
),
a_ids as (
select artist_name,
artist_id
from {{ ref('dim_artists') }}
),
fct_top_tracks as (
select ranking,
(
select distinct artist_id
from a_ids as a
where a.artist_name = stg.artist_name
) as artist_id,
track_id,
listens_count,
valid_from,
valid_to
from staging as stg
)
select *
from fct_top_tracks
Now the whole process can be activated from the cli:
dbt snapshot
dbt run
As we can see no errors here:
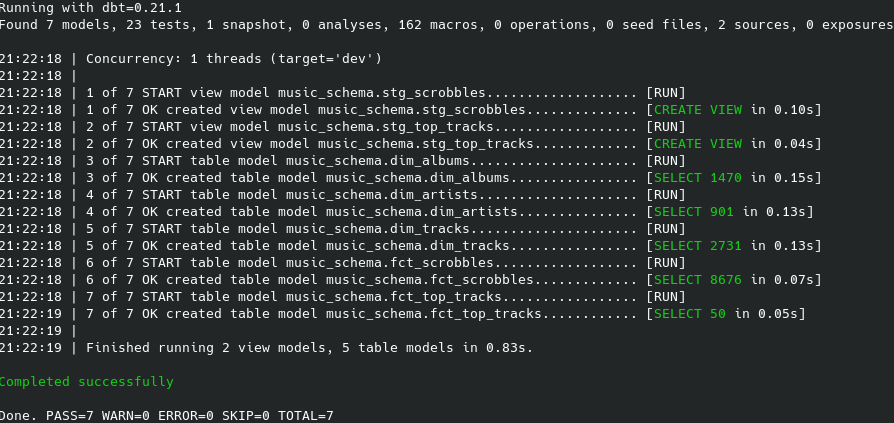
It is important to take a snapshot before the run command because it is a source for a staging table. Now the snapshot and core models should be materialized as tables and the staging table as a view. To run a previously defined tests dbt requires just a simple command:
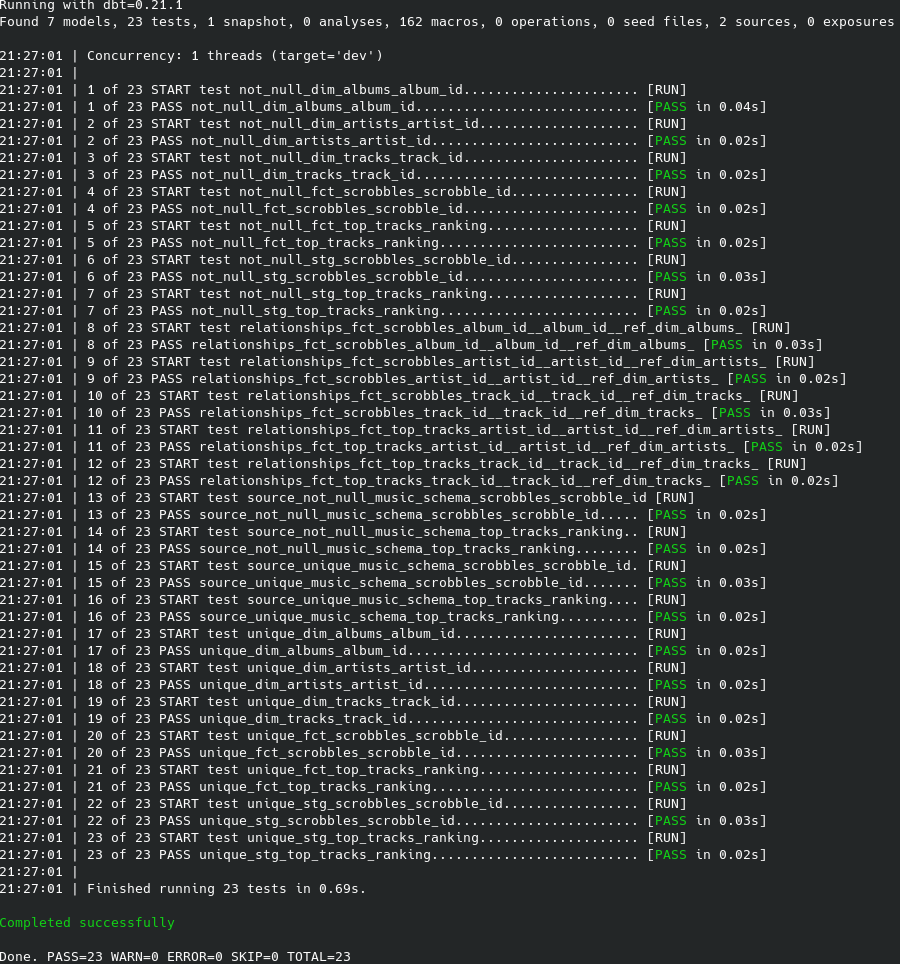
dbt test
As we can see every test passed, so everything works.
Docs
Dbt gives an easy way to generate and serve documentation:
dbt docs generate
dbt docs serve
From here, the defined descriptions, tests, SQL statements, and the Directed Acyclic Graph (DAG) can be accessed.
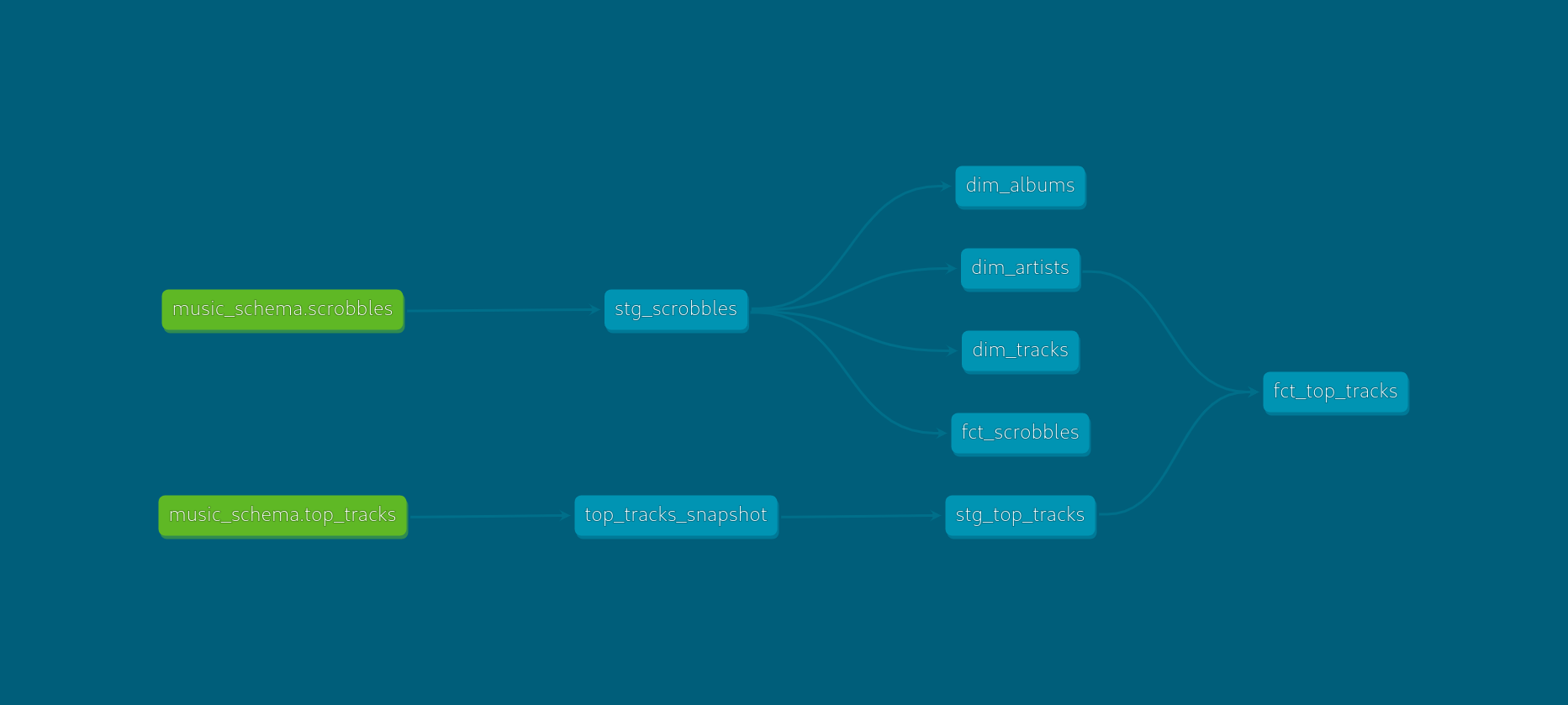
Schedule
The whole process is scheduled in the airflow. The DAG is not production-ready. I do not recommend scheduling dbt at the project level with BashOperator for a production. It is ok only for testing, simple use cases, or learning. It has issues like for example absolute failures so the cost of running a serious process would be HUGE. The observability of the execution state is also not so good. However this is a learning project for me, so I suppose it is fine. My example DAG looks like this:
from datetime import datetime, timedelta
from airflow import DAG
from airflow.models import Variable
from airflow.operators.python_operator import PythonOperator
from airflow.operators.bash import BashOperator
from extract_load import get_song_plays, get_top_tracks
default_args = {
'dag_id': 'music_elt',
'owner': 'Brozen',
'depends_on_past': False,
'start_date': datetime(2022, 4, 5),
'retries': 1,
'retry_delay': timedelta(minutes=2)
}
dag = DAG(
'music_dag',
default_args=default_args,
description='Music ELT',
schedule_interval=timedelta(days=7)
)
t1 = PythonOperator(
task_id='get_song_plays',
python_callable=get_song_plays,
op_kwargs=Variable.get("music_vars", deserialize_json=True),
dag=dag
)
t2 = PythonOperator(
task_id='get_top_tracks',
python_callable=get_top_tracks,
op_kwargs=Variable.get("music_vars", deserialize_json=True),
dag=dag
)
t3 = BashOperator(
task_id='dbt_snapshot',
bash_command='cd ~/music_elt/music_elt_dbt && dbt snapshot',
dag=dag
)
t4 = BashOperator(
task_id='dbt_run',
bash_command='cd ~/music_elt/music_elt_dbt && dbt run',
dag=dag
)
t5 = BashOperator(
task_id='dbt_tests',
bash_command='cd ~/music_elt/music_elt_dbt && dbt test',
dag=dag
)
t1 >> t2 >> t3 >> t4 >> t5
This DAG is basic, I would never use it in the production environment. The process is scheduled to run at 7 days intervals. Python operators use airflow environment variables as functions’ arguments. The graph is also really straightforward:

Conclusion
The most valuable outcome from this project for me is a thing that dbt is a super cool tool that makes life easier. I will use it a lot and try to master it. However, the project was a disaster. Data from the Last FM API has a lot of holes and is hard to work with. I should use a Spotify API. I even wanted to change it, but after a quick research, I noticed that there are quite similar projects with that API. The project does not have any other value than tools’ knowledge also. It is just useless. I am not so happy. I hope I will create a better project with dbt shortly. Wish me luck!
References
- https://www.astera.com/type/blog/etl-vs-elt-whats-the-difference/
- https://www.integrate.io/blog/etl-vs-elt/
- https://www.startdataengineering.com/post/elt-vs-etl/
- https://www.analytics8.com/blog/dbt-overview-what-is-dbt-and-what-can-it-do-for-my-data-pipeline/#
- https://www.startdataengineering.com/post/dbt-data-build-tool-tutorial/
- https://www.startdataengineering.com/post/how-to-join-fact-scd2-tables/
- https://docs.getdbt.com/docs/building-a-dbt-project/snapshots#check-strategy
- https://towardsdatascience.com/the-most-efficient-way-to-organize-dbt-models-244e23c17072
- https://docs.getdbt.com/blog/how-we-structure-our-dbt-projects/#describing-a-business-through-marts
- https://www.astronomer.io/guides/airflow-dbt/