GrandPrix Circus - MongoDB and FastAPI
Introduction
Hello, long time no see. In the new series of posts I will create a new mobile application - Grand Prix Circus. It will be embedding social media posts from sites like Instagram, Twitter or YouTube. The user will also have the possibility to create their own posts, give a like or dislike reaction, or comment on the other posts. The content should be a mix of facts and memes. It is fair to say it will be quite a clone of a classic social media feed. The whole front-end part will be created using Flutter. The back end will be rather simple. The heart of it will be the document type MongoDB database. know that the app will have a lot more read requests than the write requests, but the documents won’t be nested. They will just store some basic data about the posts, comments, or user reactions. The programming interface for the database will be created using Fast API. It will cover the basic CRUD methods and will also give a bit more complicated endpoints. The only trick is that the posts from social media will be automatically collected by bots created with Selenium (I hope they won’t get banned so fast). The bots will be also configured as ZeroMQ producers. They will send the scrapped results to the consumer who will write it to the database using an API. I won’t load a lot of data, I think the bots will run maybe two times a day, and together they will produce maybe 50 documents daily. It could work without the message queue, but I would like to try it. Maybe I can mimic the randomness of post-creation. I mean the whole content from a specific bot won’t be uploaded at almost the same timestamp. The queue will process it one by one, with a fixed timestamp. It will also minimize the load on the API, although the Fast API is asynchronous by design and I will also use the asynchronous Motor driver for MongoDB. I will also try to secure API a bit, but without over-killing. The API service will be deployed with the Caddy web server, which will give us the TLS and certification with Let’s Encrypt. Everything except the mobile app will be containerized using Docker. For user authentication and storing the files, I will use Firebase. It is a platform for app development from Google. It has a free plan which is good for trying things out. I do not like the not open source tools but it is good to have some knowledge about the Firebase in the mobile apps world. I still recommend Appwrite as the open-source solution. That’s how the provisional high-level architecture diagram would look:
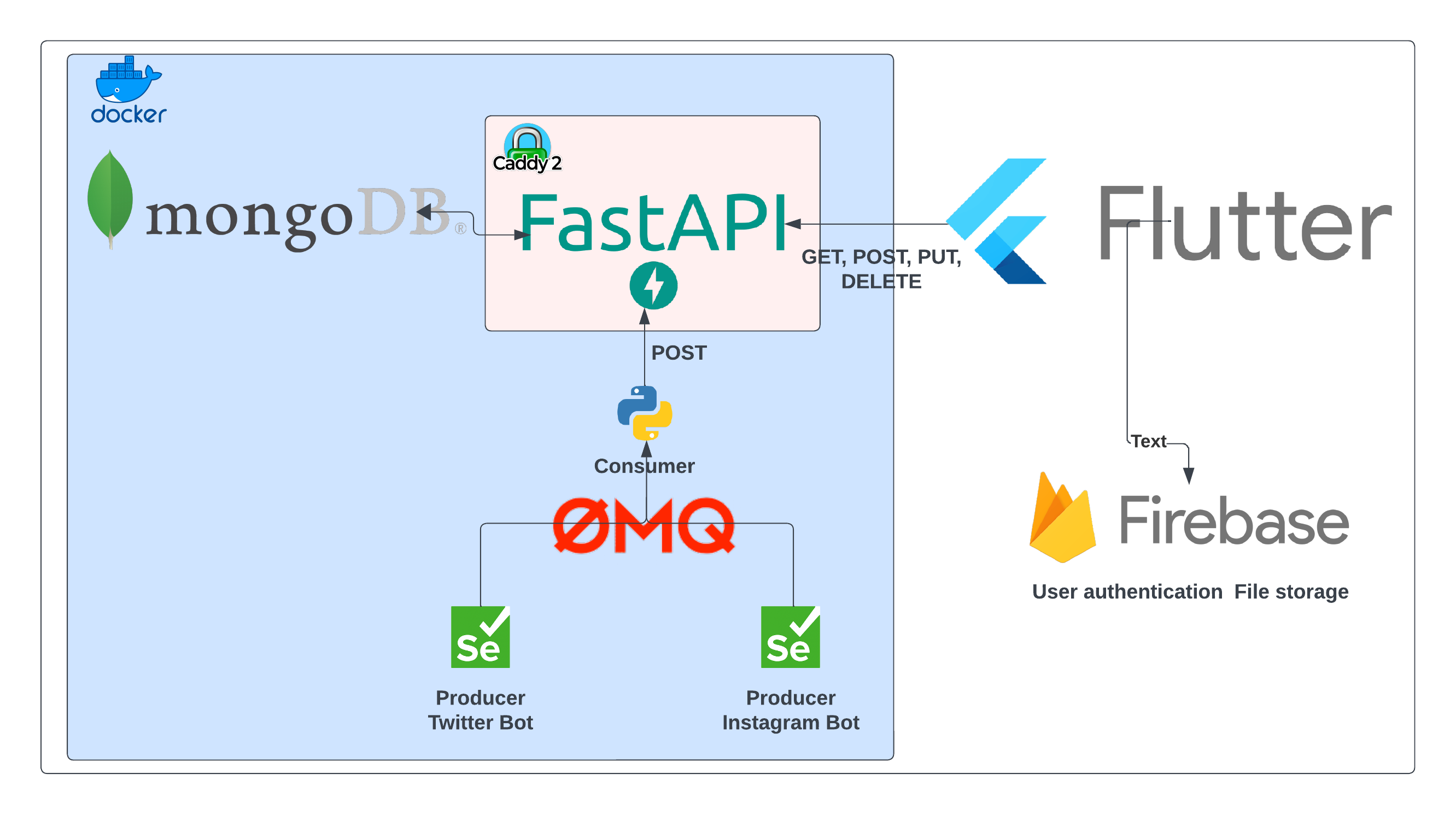 In this post, I will deploy the MongoDB database and create the API for it.
In this post, I will deploy the MongoDB database and create the API for it.
Let’s get to work!
MongoDB
This task is pretty simple as long as the database is deployed for development purposes only. The docker-compose might look like this:
version: '3.8'
services:
dbgate:
image: dbgate/dbgate
container_name: dbgate
restart: always
ports:
- 3000:3000
volumes:
- dbgate-data:/root/.dbgate
environment:
LOGINS: charizard_dbgate
LOGIN_PASSWORD_charizard_dbgate: ${DBG_PASSWORD}
CONNECTIONS: con1
LABEL_con1: MongoDB
URL_con1: ${MONGO_AUTH}
ENGINE_con1: mongo@dbgate-plugin-mongo
mongodb:
image: mongo
container_name: mongodb
environment:
- MONGO_INITDB_ROOT_USERNAME=${MONGO_ADMIN}
- MONGO_INITDB_ROOT_PASSWORD=${MONGO_PASS}
volumes:
- mongo-data:/data/db
ports:
- 27017:27017
restart: unless-stopped
command: [ --auth ]
volumes:
mongo-data:
name: mongo-data
dbgate-data:
driver: local
Now the MongoDB instance should be accessible on the local host. As you can see I am using the DBGate as a graphical interface instead of Mongo Express. I really like this tool, I use it daily. It works with various database management systems and is operating system agnostic. The user interface is not required, it is just for convenience. In the production version, I would map the host machine ports to the container ones. The database will be in the same docker network with its API. I will use a web server, so API and DBGate will stay behind reverse proxy. For the local development, the compose file above is enough, it should work without problems. The composition with the Caddy web server could look like this:
services:
dbgate:
image: dbgate/dbgate
container_name: dbgate
restart: always
expose:
- 3000
volumes:
- dbgate-data:/root/.dbgate
environment:
LOGINS: charizard_dbgate
LOGIN_PASSWORD_charizard_dbgate: ${DBG_PASSWORD}
CONNECTIONS: con1
LABEL_con1: MongoDB
URL_con1: ${MONGO_AUTH}
ENGINE_con1: mongo@dbgate-plugin-mongo
networks:
- gp-circus-backend
- caddy-network
mongodb:
image: mongo
container_name: mongodb
environment:
- MONGO_INITDB_ROOT_USERNAME=${MONGO_ADMIN}
- MONGO_INITDB_ROOT_PASSWORD=${MONGO_PASS}
volumes:
- mongo-data:/data/db
expose:
- 27017
restart: unless-stopped
command: [ --auth ]
networks:
- gp-circus-backend
caddy:
image: caddy:alpine
container_name: caddy
ports:
- 80:80
- 443:443
volumes:
- ./Caddyfile:/etc/caddy/Caddyfile
- ./data:/data
- ./config:/config
networks:
- caddy-network
restart: unless-stopped
volumes:
mongo-data:
name: mongo-data
dbgate-data:
driver: local
networks:
gp-circus-backend:
name: gp-circus-backend
caddy-network:
name: caddy-network
Caddyfile should contain an entry with the domain name for the DBGate service, for example:
dbgate.domain_name.com {
reverse_proxy dbgate:3000
}
The implementation is still not production-ready. In the real world, the database would need some other security improvements, for example, better permissions control.
FastAPI
The API will have three routes: posts, reactions, and comments. The routes will have the following endpoints:
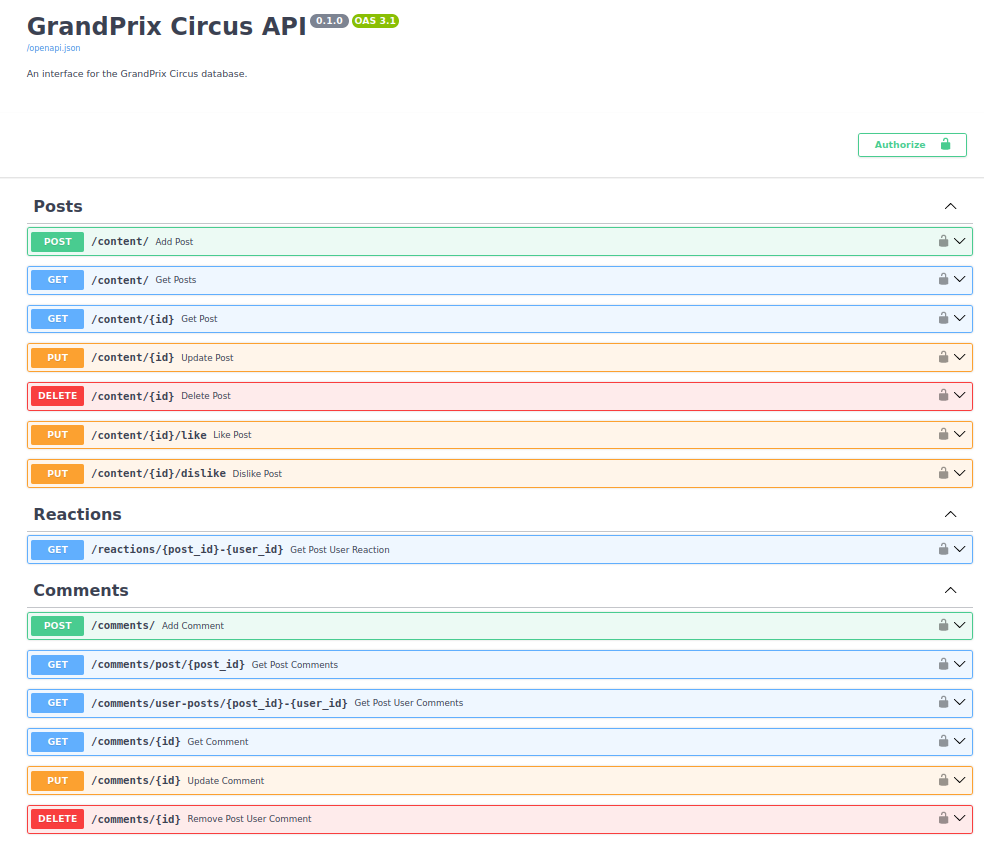
I think their names are self-explainable.
Let’s start with creating data models for posts and reactions with pydantic. The post model will have 9 fields:
- id - the id assigned by MongoDB,
- content id - the unique identifier of the resource. It has a string type because it can be different in each source. To be honest it could be a URL if required,
- creation time,
- title,
- author - name of the social media content author or user identifier,
- tag - it will identify the source of the content, eg. tweet or insta,
- source - the URL of the author’s social media page or user,
- likes count - number of likes,
- dislikes count - number of dislikes.
from typing import Optional, List
from typing_extensions import Annotated
from pydantic import BaseModel, Field, ConfigDict
from pydantic.functional_validators import BeforeValidator
from bson import ObjectId
PyObjectId = Annotated[str, BeforeValidator(str)]
class PostSchema(BaseModel):
id: Optional[PyObjectId] = Field(alias="_id", default=None)
contentId: str = Field(...)
creationTime: str = Field(...)
title: str = Field(...)
author: str = Field(...)
tag: str = Field(...)
source: str = Field(...)
likesCount: int = Field(default=0, ge=0)
dislikesCount: int = Field(default=0, ge=0)
model_config = ConfigDict(
populate_by_name=True,
json_schema_extra={
"example": {
"id": "65528d772a0fb59c46931079",
"contentId": "42348s1234934asmqwe",
"creationTime": "2023-11-02T14:30:00",
"title": "Chris Medland posted new tweet!",
"author": "ChrisMedlandF1",
"tag": "tweet",
"source": "https://twitter.com/ChrisMedlandF1/status/1719722702125031687",
"likesCount": 0,
"dislikesCount": 0,
}
},
)
class UpdatePostSchema(BaseModel):
contentId: Optional[str] = None
creationTime: Optional[str] = None
title: Optional[str] = None
author: Optional[str] = None
tag: Optional[str] = None
source: Optional[str] = None
likesCount: Optional[int] = None
dislikesCount: Optional[int] = None
model_config = ConfigDict(
json_encoders={ObjectId: str},
json_schema_extra={
"example": {
"contentId": "42348s1234934asmqwe",
"creationTime": "2023-11-03T14:30:00",
"title": "Chris Medland posted a new tweet!",
"author": "ChrisMedlandF1",
"tag": "tweet",
"source": "https://twitter.com/ChrisMedlandF1/status/1719722702125031687",
"likesCount": 0,
"dislikesCount": 0,
}
},
)
class PostsCollection(BaseModel):
posts: List[PostSchema]
If the attribute has the Field(...) it means it’s required. The likes fields are 0 by default and cannot be less. I also like to create a separate model for the entities that can have a lot of fields modified, it makes the code more maintainable. The PostsCollection model will be returned by the GET method without the specified id of the post.
The reaction model is smaller. It has only 4 fields:
- id - the id assigned by MongoDB,
- user id - the id of the user that gave a reaction,
- post id -the id of the liked/disliked post,
- reactionType - it can be one of the three values:
- 1 - like,
- 0 - dislike,
- -1 - not set
The -1 might look weird because if the user didn’t react the document for his reaction should not exist. The point is the user can react and then undo it. I prefer to change the reaction type to -1 then instead of deleting the whole document. It will be easier to manage from the front-end side.
from typing import Optional, List
from typing_extensions import Annotated
from pydantic import BaseModel, Field, ConfigDict
from pydantic.functional_validators import BeforeValidator
from bson import ObjectId
PyObjectId = Annotated[str, BeforeValidator(str)]
class ReactionModel(BaseModel):
id: Optional[PyObjectId] = Field(alias="_id", default=None)
userId: str = Field(...)
postId: str = Field(...)
reactionType: int = Field(ge=-1, le=1, default=-1)
model_config = ConfigDict(
populate_by_name=True,
json_schema_extra={
"example": {
"id": "6553b385dc8f5011550a237c",
"userId": "5",
"postId": "65528d772a0fb59c46931079",
"reactionType": "0",
}
},
)
class ReactionsCollection(BaseModel):
reactions: List[ReactionModel]
The model for a comment has six fields:
- id - the id assigned by MongoDB,
- user id - id of the post creator,
- user name - the name of the post creator,
- post id - id of the commented post,
- comment - the comment text,
- creation time.
It has separated classes for the updated entry and a collection of entities.
class CommentModel(BaseModel):
id: Optional[PyObjectId] = Field(alias="_id", default=None)
userId: str = Field(...)
userName: str = Field(...)
postId: str = Field(...)
comment: str = Field(...)
creationTime: str = Field(...)
model_config = ConfigDict(
populate_by_name=True,
json_schema_extra={
"example": {
"id": "6553b385dc8f5011550a237c",
"userId": "5",
"userName": "Brozen",
"postId": "65528d772a0fb59c46931079",
"comment": "Super!",
"creationTime": "2023-11-02T14:30:00"
}
},
)
class UpdatedCommentSchema(BaseModel):
userId: Optional[str] = None
userName: Optional[str] = None
postId: Optional[str] = None
comment: Optional[str] = None
model_config = ConfigDict(
json_encoders={ObjectId: str},
json_schema_extra={
"example": {
"id": "6553b385dc8f5011550a237c",
"userName": "Brozen",
"userId": "5",
"postId": "65528d772a0fb59c46931079",
"comment": "Super Super!",
"creationTime": "2023-11-02T14:30:00"
}
},
)
class CommentsCollection(BaseModel):
comments: List[CommentModel]
The first post route will return post collection. It is paginated, using a classic combination of skip and limit. I also reversed the collection, so the first page will have the newest content. The id is always indexed, so this operation should be not that slow.
@post_router.get(
"/",
response_description="Posts retrieved",
response_model=PostsCollection,
response_model_by_alias=False,
)
async def get_posts(page: int = 1, limit: int = 10):
posts = (
await collection.find()
.sort({"_id": -1})
.skip((page - 1) * limit)
.limit(limit)
.to_list(None)
)
return PostsCollection(posts=posts)
The add_post method is straightforward. It just inserts one document into the collection.
@post_router.post(
"/", response_description="A new post content added to the collection"
)
async def add_post(post: PostSchema = Body(...)):
post = post.model_dump(by_alias=True, exclude=["id"])
new_post = await collection.insert_one(post)
return "Success"
The endpoint for obtaining a single post by id will return it if it exists. A not-valid object id case is also handled.
@post_router.get(
"/{id}",
response_description="Post retrieved",
response_model=PostSchema,
response_model_by_alias=False,
)
async def get_post(id: str):
try:
post = await collection.find_one({"_id": ObjectId(id)})
except errors.InvalidId:
raise HTTPException(
status_code=404,
detail=f"Post {id} is not a valid ObjectId, it must be a 12-byte input or a 24-character hex string",
)
if post is not None:
return post
raise HTTPException(
status_code=404, detail=f"Post {id} not found in the collection"
)
The method for updating the post will work when the post exists and someone is not trying to pass the update with all empty fields.
@post_router.put(
"/{id}",
response_description="Post updated",
response_model=PostSchema,
response_model_by_alias=False,
)
async def update_post(id: str, post: UpdatePostSchema = Body(...)):
post = {k: v for k, v in post.model_dump(by_alias=True).items() if v is not None}
if len(post) < 1:
return False
update_post = await collection.find_one_and_update(
{"_id": ObjectId(id)}, {"$set": post}, return_document=True
)
if update_post is not None:
return update_post
raise HTTPException(
status_code=404, detail=f"Post {id} not found in the collection"
)
The delete posts method works similarly.
@post_router.delete("/{id}", response_description="Post deleted")
async def delete_post(id: str):
delete_result = await collection.delete_one({"_id": ObjectId(id)})
if delete_result.deleted_count == 1:
return Response(status_code=status.HTTP_204_NO_CONTENT)
raise HTTPException(
status_code=404, detail=f"Post {id} not found in the collection"
)
Methods for handling reactions are a bit more complicated, but also simple. It is required to understand how the user interface will work. If the user likes a post without any previous reaction, the likes counter should be incremented by one. If the user already had the opposite reaction, the dislikes counter should be decremented by one, and the likes counter incremented by one. If the user already liked the post and the thumb-up icon is clicked again it should decrement the likes counter. If it’s the first reaction for the selected post the document in the reactions collection is created, otherwise updated. The dislike method follows the same logic.
@post_router.put(
"/{id}/like",
response_description="Post liked",
response_model=ReactionModel,
response_model_by_alias=False,
)
async def like_post(id: str, user_id: str):
disliked_reaction = await reactions.find_one(
{"postId": id, "userId": user_id, "reactionType": 0}
)
if disliked_reaction:
await collection.find_one_and_update(
{"_id": ObjectId(id)}, {"$inc": {"dislikesCount": -1}}
)
existing_like = await reactions.find_one(
{"postId": id, "userId": user_id, "reactionType": 1}
)
if existing_like:
await collection.find_one_and_update(
{"_id": ObjectId(id)}, {"$inc": {"likesCount": -1}}
)
updated_reaction = await reactions.find_one_and_update(
{"postId": id, "userId": user_id},
{
"$set": ReactionModel(
postId=id, userId=user_id, reactionType=-1
).model_dump(by_alias=True, exclude=["id"])
},
upsert=True,
return_document=True,
)
else:
await collection.find_one_and_update(
{"_id": ObjectId(id)}, {"$inc": {"likesCount": 1}}, return_document=True
)
updated_reaction = await reactions.find_one_and_update(
{"postId": id, "userId": user_id},
{
"$set": ReactionModel(
postId=id, userId=user_id, reactionType=1
).model_dump(by_alias=True, exclude=["id"])
},
upsert=True,
return_document=True,
)
return updated_reaction
raise HTTPException(
status_code=404, detail=f"Post {id} not found in the collection"
)
@post_router.put(
"/{id}/dislike",
response_description="Post disliked",
response_model=ReactionModel,
response_model_by_alias=False,
)
async def dislike_post(id: str, user_id: str):
liked_reaction = await reactions.find_one(
{"postId": id, "userId": user_id, "reactionType": 1}
)
if liked_reaction:
await collection.find_one_and_update(
{"_id": ObjectId(id)}, {"$inc": {"likesCount": -1}}
)
existing_dislike = await reactions.find_one(
{"postId": id, "userId": user_id, "reactionType": 0}
)
if existing_dislike:
await collection.find_one_and_update(
{"_id": ObjectId(id)}, {"$inc": {"dislikesCount": -1}}
)
updated_reaction = await reactions.find_one_and_update(
{"postId": id, "userId": user_id},
{
"$set": ReactionModel(
postId=id, userId=user_id, reactionType=-1
).model_dump(by_alias=True, exclude=["id"])
},
upsert=True,
return_document=True,
)
else:
await collection.find_one_and_update(
{"_id": ObjectId(id)}, {"$inc": {"dislikesCount": 1}}, return_document=True
)
updated_reaction = await reactions.find_one_and_update(
{"postId": id, "userId": user_id},
{
"$set": ReactionModel(
postId=id, userId=user_id, reactionType=0
).model_dump(by_alias=True, exclude=["id"])
},
upsert=True,
return_document=True,
)
return updated_reaction
raise HTTPException(
status_code=404, detail=f"Post {id} not found in the collection"
)
I would like to create only one reaction endpoint - for getting the user reaction for the specified post. The app will use it to check if the authenticated user already reacted to the post.
@reaction_router.get(
"/{post_id}-{user_id}",
response_description="Reaction retrieved",
response_model=ReactionModel,
response_model_by_alias=False,
)
async def get_post_user_reaction(post_id: str, user_id: str):
reaction = await reactions.find_one({"postId": post_id, "userId": user_id})
if reaction is not None:
return reaction
raise HTTPException(
status_code=404, detail="Post and user combination not found in the collection"
)
The comments endpoints cover a complete CRUD and give the methods for retrieving a list of comments for a post (paginated) or a specified user.
@comment_router.post(
"/", response_description="A new comment added to the collection"
)
async def add_comment(comment: CommentModel = Body(...)):
comment = comment.model_dump(by_alias=True, exclude=["id"])
new_comment = await comments.insert_one(comment)
return "Success"
@comment_router.get(
"/post/{post_id}",
response_description="Comments retrieved",
response_model=CommentsCollection,
response_model_by_alias=False,
)
async def get_post_comments(post_id: str, limit: int = 5, page: int = 1):
comments_data = (await
comments.find({"postId": post_id})
.sort({"_id": -1})
.skip((page - 1) * limit)
.limit(limit)
.to_list(None)
)
return CommentsCollection(comments=comments_data)
@comment_router.get(
"/user-posts/{post_id}-{user_id}",
response_description="Comments retrieved",
response_model=CommentsCollection,
response_model_by_alias=False,
)
async def get_post_user_comments(post_id: str, user_id: str):
comments_list = await comments.find({"postId": post_id, "userId": user_id}).to_list(None)
return CommentsCollection(comments=comments_list)
@comment_router.get(
"/{id}",
response_description="Comment retrieved",
response_model=CommentModel,
response_model_by_alias=False,
)
async def get_comment(id: str):
try:
comment = await comments.find_one({"_id": ObjectId(id)})
except errors.InvalidId:
raise HTTPException(
status_code=404,
detail=f"Comment {id} is not a valid ObjectId, it must be a 12-byte input or a 24-character hex string",
)
if comment is not None:
return comment
raise HTTPException(
status_code=404, detail=f"Comment {id} not found in the collection"
)
@comment_router.put(
"/{id}",
response_description="Comment updated",
response_model=CommentModel,
response_model_by_alias=False,
)
async def update_comment(id: str, comment: UpdatedCommentSchema = Body(...)):
comment = {k: v for k, v in comment.model_dump(by_alias=True).items() if v is not None}
if len(comment) < 1:
return False
update_comment = await comments.find_one_and_update(
{"_id": ObjectId(id)}, {"$set": comment}, return_document=True
)
if update_comment is not None:
return update_comment
raise HTTPException(
status_code=404, detail=f"Comment {id} not found in the collection"
)
@comment_router.delete(
"/{id}", response_description="Reaction retrieved"
)
async def remove_post_user_comment(id: str):
delete_result = await comments.find_one_and_delete(
{"_id": ObjectId(id)}
)
if delete_result:
return Response(status_code=status.HTTP_204_NO_CONTENT)
raise HTTPException(
status_code=404, detail=f"Post {post_id} not found in the collection"
)
To authorize the endpoints I will just use the API key in the request header. It does not provide security at all but can be one of the security system layers. My application is just a learning project, so it does not need to be production-ready. For example, if I would like to release it on Google Play it could be important to take a look at the OAuth2 Authentication Code with PKCE flow, some hashing, and a better way to store secrets. For now, secrets are stored just using the environment variables passed in the docker-compose from .env file. To cover all endpoints with the same API key just inject the dependency to the whole app. It is also possible to cover certain endpoints with different API keys.
app = FastAPI(
title="GrandPrix Circus API",
summary="An interface for the GrandPrix Circus database.",
dependencies=[Depends(check_api_key)]
)
Let’s also create a file for database connection:
import os
import motor.motor_asyncio
import pymongo
DB_URL = os.environ["DATABASE_URL"]
client = motor.motor_asyncio.AsyncIOMotorClient(
DB_URL
)
db = client["gpcircus"]
reactions = db["reactions"]
comments = db["comments"]
db.reactions.create_index([("post_id", 1), ("user_id", 1)])
db.comments.create_index([("post_id", 1), ("user_id", 1)])
collection = db["content"]
Indexes on collection fields match the search patterns used by applications for comments and reactions. The routers should be also included in the app:
app.include_router(post_router, tags=["Posts"], prefix="/content")
app.include_router(reaction_router, tags=["Reactions"], prefix="/reactions")
app.include_router(comment_router, tags=["Comments"], prefix="/comments")
In the main file just give an instruction to run the app with Uvicorn. The proxy headers should be true because the API will use a Caddy load balancer. The reload parameter is just to refresh on changes, for local development.
import uvicorn
if __name__ == "__main__":
uvicorn.run("app:app", host="0.0.0.0", port=8000, reload=True, proxy_headers=True)
Now let’s add the API service to the docker-compose:
gpc-api:
build: ./api_service
container_name: gpc-api
environment:
- DATABASE_URL=${MONGO_AUTH}
- API_KEY=${API_KEY}
ports:
- 8000:8000
Accessing the /docs path it should look like this:
Conclusion
Creating a simple API for local development is pretty straightforward, especially using FastAPI. This implementation is not production ready and it would not scale well for a large user audience. It could be more secure also. The Mongo database instance could have a more complicated implementation for production. For my development purposes, it is enough, that the application client will be able to communicate with the database on a server easily. In the next post, I will create the Selenium bots for scraping social media and the ZMQ services. Cya!