Find Nursery - simple app with analytics
Introduction
Long time no see! I haven’t been dedicating enough time to my blog lately due to starting a new job as a product manager. As you can imagine, it’s not my dream role, but I want to excel in it, so it’s consuming a lot of energy. In this post, I’ll create a simple Flutter application, log various analytical events using Firebase, and showcase a few analytical queries in BigQuery. In my professional journey, I’ve delved into a variety of analyses using Firebase event logging, on a significantly broader scale and I’d say I’ve got a pretty good knack for it. The application will be a simple daycare search engine in Poland, with a bookmarks and articles sections. You might wonder why? On the government’s website, you can find various interesting data related to a wide range of public activities in Poland. Daycare data is one of them, not structured in the best way, and it will be possible to parse it using regular expressions. After that, the goal is to find their geographical coordinates using the Nominatim API. An important factor is that I can create such an application very quickly, in just a few hours. My main goal is to demonstrate that I can work analytically with applications using Firebase.
Let’s get to work!
ETL
Let’s start with retrieving the data. I managed to find an XML file indicating the last data update. Based on this date, you can determine whether to fetch new data, especially if the process is to be scheduled, for instance, using Airflow or a regular CRON job. Google Cloud provides options for executing code at specified intervals, such as Cloud Scheduler or Cloud Composer. I won’t be demonstrating these in this post (I’ve covered Cloud Scheduler a bit in this post). Let’s download the XML using the requests library and create a dictionary from it using a simple function:
xml_map = r.get('https://rejestrzlobkow.mpips.gov.pl/RZ-metadane-instytucje.xml')
root = ET.fromstring(xml_map.text)
def element_to_dict(element) -> dict:
result = {}
for child in element:
if child:
child_data = element_to_dict(child)
else:
child_data = child.text
result[child.tag] = child_data
return result
xml_dict = element_to_dict(root)
You can also save the last data update date to a variable and make further code execution dependent on it. I won’t do it in this post, but in the context of creating a real application, it would be worth implementing.
last_update_date = xml_dict['dataset']['lastUpdateDate']
Let’s move on to address transformation. In the column from the downloaded file, the address is likely manually provided by the individuals managing the daycare center. With around 6 thousand entries, addresses can be diverse. For Nominatim, it’s preferable to have just the city and street along with the building number. Otherwise, it might not return any result. In the file, the address contains several pieces of information separated by ‘>’, such as city > county > municipality > address. I’m interested only in the last piece of information. Typically, there are words like “avenue,” “district,” “housing estate,” or “square” in this part of the address. Nominatim doesn’t handle them well, so they need to be removed. It’s also a good idea to set up some conditions for various edge cases and eliminate unnecessary spaces.
def transform_address(address: str) -> str:
try:
address = address.split('>')[-1]
address = re.sub(r'ul[.\s]|ulica|delegatura|dzielnica m. st. Warszawy|(M|m)iasto|al[.\s]|aleja|\swie[sś]|ks[.\s]|inf[.\s]|skwer|osada|os[.\s]|osiedle|gen[.\s]|,', ' ', address)
lok_pattern = re.compile(r'lok\..*')
address = re.sub(r'-\s*[^ ]* ', " ", address)
address = re.sub(r'Pole|Huta', ' ', address)
address = re.sub(lok_pattern, " ", address)
address = re.sub(r'\s+', ' ', address)
return address
except Exception as e:
print(f'Some error with transformation: {e}')
Now, let’s create a function that queries the Nominatim API for coordinates based on a given address, utilizing the geopy library. I’ll introduce a 3-second sleep within the loop to avoid overusing Nominatim servers.
def map_coordinates(address: str) -> tuple[float]:
try:
time.sleep(3)
geolocator = Nominatim(user_agent='brozen.best')
location = geolocator.geocode(address)
print(f'{address}: success')
return (location.latitude, location.longitude)
except Exception as e:
print(f'Some mapping error" {e}')
Let’s download and parse the data, and create a Pandas DataFrame from it:
url = xml_dict['dataset']['resources']['resource']['url']
res = r.get(url)
content = res.content.decode('utf-8')
df = pd.read_csv(StringIO(content),on_bad_lines = 'warn', sep=';')
df['transformed_address'] = df['Lokalizacja instytucji'].map(lambda x: transform_address(x))
df[['lat', 'lon']] = df['transformed_address'].apply(lambda x: pd.Series(map_coordinates(x)))
Data downloaded and transformed, now let’s load it into Firestore, which will serve as the database for our application. In the free version of Firebase, there is a limit of 50,000 reads per day. In production, this might be insufficient, but for the purposes of this mini-project, it should be adequate.
cred = credentials.Certificate('./credentials.json')
app = firebase_admin.initialize_app(cred)
db = firestore.client()
collection = db.collection("nurseries")
# change NaN to None, because Firestore will treat NaN as Number type
df = df.replace(np.nan, None)
df_dict = df.to_dict('index')
for d, x in df_dict.items():
working_hours = x['Godziny otwarcia'].replace('Godziny pracy: ', '').split(', ')
working_hours_dict = {}
if len(working_hours) > 1:
for a in working_hours:
a = a.split(' ')
if len(a) > 1:
working_hours_dict[a[0]] = a[1]
else:
working_hours_dict[a[0]] = working_hours[-1].split(' ')[1]
if x['lat'] and x['lon']:
doc = {
'name': x['Nazwa'],
'alimentationDailyFee': x['Opłata za wyżywienie - dzienna'],
'alimentationMonthlyFee': x['Opłata za wyżywienie - miesięczna'],
'email': x['E-mail żłobka/klubu'],
'discounts': x['Zniżki'],
'institutionLocation': x['Lokalizacja instytucji'].split('>')[-1].strip(),
'institutionType': x['Typ instytucji'],
'location': {'geohash': geohash.encode(x['lat'], x['lon'], precision=12), 'geopoint': firestore.GeoPoint(x['lat'], x['lon'])},
'monthlyFee': x['Opłata miesięczna - podstawowa opłata ponoszona przez rodziców za pobyt dziecka (bez zniżek i bez wyżywienia)'],
'hourlyFee': x['Opłata godzinowa - podstawowa opłata ponoszona przez rodziców za pobyt dziecka (bez zniżek i bez wyżywienia)'],
'numberOfPlaces': int(x['Liczba miejsc']) if x['Liczba miejsc'] else None ,
'numberOfPlacesTaken': int(x['Liczba dzieci zapisanych']) if x['Liczba dzieci zapisanych'] else None,
'operatingEntityAddress': x['Podmiot prowadzacy - adres'],
'operatingEntityNIP': str(x['Podmiot prowadzący - NIP']),
'operatingEntityName': x['Podmiot prowadzący - nazwa'],
'operatingEntityRegon': x['Podmiot prowadzący - REGON'],
'operatingEntityRegistryNumber': x['Podmiot prowadzący - numery pozycji rejestru'],
'overTenHoursHourlyFee': x['stawka za pobyt dziecka przekraczający 10 godzin dziennie - opłata godzinowa'],
'phoneNumber': x['Telefon żłobka/klubu'],
'specialTreatment': True if x['Czy żłobek/klub jest dostosowany do potrzeb dzieci niepełnosprawnych lub wymagających szczególnej opieki?'] == 'TAK' else False,
'suspended': True if x['Czy podmiot prowadzący zawiesił działalność gospodarczą?'] == 'TAK' else False,
'websiteUrl': x['Adress WWW żłobka/klubu'],
'workingHours': working_hours_dict
}
collection.add(doc)
As you can see, for the opening hours, which are in the data as simple text strings, I create a special object where each day has separate time slots. If there are no specified hours for a particular day in the base string, the time is assigned from the next day. It’s an odd format for entering data into Excel, but manageable.
Data loaded, so I can proceed to create the application.
Application
The application is quite simple, and I don’t plan to expand it in the future. Therefore, the code will be divided quite straightforwardly into the following folders:
- commons - for helper functions or frequently used simple widgets,
- core - for basic providers or various constant values,
- data - for code handling communication with various data sources or external services,
- domain - for data models,
- presentation - for code related to views and controllers.
It’s not the most scalable way to organize code for a mobile application, but for this mini-project, it’s entirely sufficient.
Domain layer
The application only requires defining one model - for daycare information. The model should include all the fields that were visible during data loading.
import 'package:cloud_firestore/cloud_firestore.dart';
import 'package:freezed_annotation/freezed_annotation.dart';
import 'package:geoflutterfire2/geoflutterfire2.dart';
import 'package:hive/hive.dart';
import 'package:znajdz_zlobek/commons/utils.dart';
part 'nursery_model.freezed.dart';
part 'nursery_model.g.dart';
@freezed
class NurseryModel with _$NurseryModel {
@HiveType(typeId: 0, adapterName: "NurseryModelAdapter")
const factory NurseryModel(
{@HiveField(0) required String? id,
@HiveField(1) required String? name,
@HiveField(2) required String? alimentationDailyFee,
@HiveField(3) required String? alimentationMonthlyFee,
@HiveField(4) required String? discounts,
@HiveField(5) required String? email,
@HiveField(6) required String institutionLocation,
@HiveField(7) required String institutionType,
@JsonKey(
toJson: LocationHelper.geoFirePointToJson,
fromJson: LocationHelper.geoFirePointFromJson)
@HiveField(8)
required GeoFirePoint? location,
@HiveField(9) required String? monthlyFee,
@HiveField(10) required String? hourlyFee,
@HiveField(11) int? numberOfPlaces,
@HiveField(12) required int? numberOfPlacesTaken,
@HiveField(13) required String? operatingEntityAddress,
@HiveField(14) required String? operatingEntityNIP,
@HiveField(15) required String? operatingEntityName,
@HiveField(16) required String? operatingEntityRegistryNumber,
@HiveField(17) required String? operatingEntityRegon,
@HiveField(18) required String? overTenHourlyFee,
@HiveField(19) required String? phoneNumber,
@HiveField(20) required bool specialTreatment,
@HiveField(21) required bool suspended,
@HiveField(22) required String? websiteUrl,
@HiveField(23) required Map<String, String> workingHours}) =
_NurseryModel;
factory NurseryModel.fromJson(Map<String, Object?> json) =>
_$NurseryModelFromJson(json);
factory NurseryModel.fromDocument(DocumentSnapshot doc) {
if (doc.data() == null) throw Exception("Document data was null");
return NurseryModel.fromJson(doc.data() as Map<String, Object?>)
.copyWith(id: doc.id);
}
}
As you can see, I’m using decorators for automatic code generation - Freezed and Hive. The first one creates typical methods used in data modeling, helping with simple data operations and serialization. The second one is related to the local non-relational Hive database and is necessary for storing data in it with a type model.
The location field additionally has a JsonKey decorator because it has a custom type geoFirePoint from the geoflutterfire library. It’s challenging to include GeoFirePoint in JSON, so Freezed also requires a helper class for this.
class LocationHelper {
static Map<String, dynamic> geoFirePointToJson(
final GeoFirePoint? geoFirePoint) {
return geoFirePoint?.data;
}
static GeoFirePoint? geoFirePointFromJson(final Map<String, dynamic>? json) {
if (json == null) {
return null;
}
final GeoPoint geoPoint = json["geopoint"] as GeoPoint;
return GeoFirePoint(geoPoint.latitude, geoPoint.longitude);
}
}
Hive is unable to handle it directly also , so I need to instruct it on how to save and retrieve data of this type by creating an adapter.
class GeoFirePointAdapter extends TypeAdapter<GeoFirePoint> {
@override
int get typeId => 32;
@override
void write(BinaryWriter writer, GeoFirePoint obj) {
writer
..write(obj.latitude)
..write(obj.longitude);
}
@override
GeoFirePoint read(BinaryReader reader) {
return GeoFirePoint(
reader.read() as double,
reader.read() as double,
);
}
}
Data layer
In the data layer, I need to create three repositories: one for Firestore, one for Hive, and one for Nominatim.
Let’s start by creating an interface for Firestore. We only need one method, which will allow fetching data from Firestore in the right way. The app will retrieve data only in one place - when the user enters their address. At that moment, the app should return the locations of nurseries in their vicinity, specifically within a five-kilometer radius. Fortunately, the geoflutterfire library handles all the complex logic for such geographic queries. You can read more about geographic queries in Firestore here.
@riverpod
FirestoreAPI firestoreAPI(FirestoreAPIRef ref) {
return FirestoreAPI(
db: ref.watch(firestoreProvider), geo: ref.watch(geoProvider));
}
abstract class IFirestoreAPI {
Future<List<NurseryModel>> getData(GeoFirePoint center);
}
class FirestoreAPI implements IFirestoreAPI {
final FirebaseFirestore _db;
final GeoFlutterFire _geo;
FirestoreAPI({required FirebaseFirestore db, required GeoFlutterFire geo})
: _db = db,
_geo = geo;
@override
Future<List<NurseryModel>> getData(GeoFirePoint center) async {
CollectionReference collectionReference = _db.collection('nurseries');
Stream<List<DocumentSnapshot>> stream = _geo
.collection(collectionRef: collectionReference)
.within(
center: center, radius: 5, field: 'location', strictMode: false);
List<DocumentSnapshot> documentList = await stream.first;
List<NurseryModel> resList = documentList.map((DocumentSnapshot document) {
return NurseryModel.fromDocument(document);
}).toList();
return resList;
}
}
I created a provider for this interface, taking two other providers as arguments. I’ve created separate providers for Firestore and Firebase Analytics instances. They have keepAlive set to true because by default, Riverpod destroys providers that are no longer in use. In this case, we want Firebase instances to be alive throughout the entire application lifecycle to avoid reconnecting multiple times and unnecessary associated costs. The provider for GeoFlutterFire is not necessary, I just created it for aesthetic reasons.
@Riverpod(keepAlive: true)
FirebaseFirestore firestore(FirestoreRef ref) {
return FirebaseFirestore.instance;
}
@Riverpod(keepAlive: true)
FirebaseAnalytics analytics(AnalyticsRef ref) {
return FirebaseAnalytics.instance;
}
@riverpod
GeoFlutterFire geo(GeoRef ref) {
return GeoFlutterFire();
}
The Hive repository should have five methods: three for bookmarks - get, remove, add - and two for the number of articles visited by the user. The count of visited articles is needed, as I would like to log this user property to Firebase.
@riverpod
HiveAPI hiveAPI(HiveAPIRef ref) {
return HiveAPI(
hiveNurseriesBox: Hive.box<NurseryModel>('nurseries'),
hiveUserPropertiesBox: Hive.box('userProperties'));
}
abstract class IHiveAPI {
List<NurseryModel>? getBookmarks();
void addBookmark(NurseryModel bookmark);
void removeBookmark(String id);
int getArticleEntriesProperty();
void incrementArticleEntriesProperty(int currentEntriesCount);
}
class HiveAPI implements IHiveAPI {
final Box<NurseryModel> _hiveNurseriesBox;
final Box _hiveUserPropertiesBox;
HiveAPI(
{required Box<NurseryModel> hiveNurseriesBox,
required Box hiveUserPropertiesBox})
: _hiveNurseriesBox = hiveNurseriesBox,
_hiveUserPropertiesBox = hiveUserPropertiesBox;
@override
List<NurseryModel>? getBookmarks() {
return _hiveNurseriesBox.values.toList();
}
@override
void addBookmark(NurseryModel bookmark) {
_hiveNurseriesBox.add(bookmark);
}
@override
void removeBookmark(String id) {
_hiveNurseriesBox.deleteAt(_hiveNurseriesBox.values
.toList()
.indexWhere((element) => element.id == id));
}
@override
int getArticleEntriesProperty() {
return _hiveUserPropertiesBox.get('articleEntries') ?? 0;
}
@override
void incrementArticleEntriesProperty(int currentEntriesCount) {
_hiveUserPropertiesBox.put('articleEntries', currentEntriesCount + 1);
}
}
The Nominatim API only needs one method allowing the retrieval of geographic information based on a string with an address.
@riverpod
NominatimAPI nominatimAPI(NominatimAPIRef ref) {
return NominatimAPI();
}
abstract class INominatimAPI {
Future<Place> search(String address);
}
class NominatimAPI implements INominatimAPI {
@override
Future<Place> search(String address) async {
final List<Place> searchResult =
await Nominatim.searchByName(query: address, limit: 1);
return searchResult.single;
}
}
Presentation layer
The presentation layer of the application is divided into three parts: finder, bookmarks, and articles.
Finder view
The finder view will be divided into two main widgets: a search form and a map (using the flutter_map package). Both will use controllers, but I’ll show that after discussing them. The search form is a straightforward text form that calls the appropriate method from the controller.
class Search extends ConsumerStatefulWidget {
const Search({super.key});
@override
ConsumerState<ConsumerStatefulWidget> createState() => _SearchState();
}
class _SearchState extends ConsumerState<Search> {
final TextEditingController adressController = TextEditingController();
@override
void dispose() {
super.dispose();
adressController.dispose();
}
@override
Widget build(BuildContext context) {
return Padding(
padding: const EdgeInsets.all(8),
child: TextFormField(
controller: adressController,
style: const TextStyle(fontSize: 11),
decoration: InputDecoration(
prefixIcon: const Icon(Icons.search),
suffixIcon: IconButton(
icon: const Icon(Icons.send),
onPressed: () {
FocusManager.instance.primaryFocus?.unfocus();
ref
.read(mapControllerProvider.notifier)
.findBoundingBox(adressController.text);
adressController.clear();
},
),
hintText: 'Podaj adres zamieszkania (ulica, miasto, kod pocztowy)',
hintStyle: const TextStyle(fontSize: 11),
contentPadding:
const EdgeInsets.symmetric(horizontal: 8, vertical: 8),
border: OutlineInputBorder(borderRadius: BorderRadius.circular(8))),
),
);
}
}
The map widget observes the state of the controller. If it has data - coordinates for the bounding box to center the map - it renders the map. If an error occurs, for example, after searching when the user enters ‘xD’ in the address field, an error message is displayed. During loading, a circular progress indicator is shown. The controller contains data of type tuple in its state. The first value contains the coordinates for centering the map, and the second value contains information about the found daycares. This list can be empty if the user hasn’t searched for anything yet. If it’s not empty, markers are drawn on the map based on the location of each daycare.
class GeoMap extends ConsumerWidget {
const GeoMap({super.key});
@override
Widget build(BuildContext context, WidgetRef ref) {
final controller = ref.watch(mapControllerProvider);
return controller.when(
data: (data) {
return FlutterMap(
options: MapOptions(
initialCameraFit: CameraFit.bounds(bounds: data.item1),
),
children: [
TileLayer(
urlTemplate: 'https://tile.openstreetmap.org/{z}/{x}/{y}.png',
userAgentPackageName: 'com.example.znajdz_zlobek',
),
MarkerLayer(
markers: data.item2.isNotEmpty
? data.item2.map((e) {
return Marker(
point: LatLng(
e.location.latitude, e.location.longitude),
child: InkWell(
child: const Icon(
size: 30,
Icons.child_friendly,
color: Colors.deepPurple,
),
onTap: () {
Navigator.push(
context,
MaterialPageRoute(
builder: (BuildContext context) =>
NurseryView(
nurseryModel: e,
)),
);
},
));
}).toList()
: [])
],
);
},
error: (error, st) {
return const Center(
child: Text(
'Niestety coś poszło nie tak 🥺\nUpewnij się, że wpisujesz prawidłowy adres i spróbuj ponownie!',
style: TextStyle(fontSize: 20),
textAlign: TextAlign.center,
),
);
},
loading: () => const Center(child: CircularProgressIndicator()));
}
}
After clicking on a marker, the user is redirected to a view with information about the selected daycare.
class NurseryView extends ConsumerWidget {
final NurseryModel nurseryModel;
const NurseryView({Key? key, required this.nurseryModel}) : super(key: key);
@override
Widget build(BuildContext context, WidgetRef ref) {
final List<NurseryModel?> bookmarks =
ref.watch(bookmarksControllerProvider);
return Scaffold(
appBar: AppBar(
title: const Text('Twój żłobek 🧸'),
centerTitle: true,
),
body: Padding(
padding: const EdgeInsets.all(8.0),
child: Column(
crossAxisAlignment: CrossAxisAlignment.start,
children: [
InfoText(label: 'Nazwa', value: nurseryModel.name),
InfoText(
label: 'Typ instytucji', value: nurseryModel.institutionType),
InfoText(
label: 'Lokalizacja instytucji',
value: nurseryModel.institutionLocation),
InfoText(
label: 'Czy podmiot zawiesił działalność gospodarczą',
value: nurseryModel.suspended ? 'Tak' : 'Nie'),
InfoText(label: 'Adres www', value: nurseryModel.websiteUrl),
InfoText(label: 'E-mail', value: nurseryModel.email),
InfoText(label: 'Telefon', value: nurseryModel.phoneNumber),
InfoText(
label: 'Liczba miejsc',
value: nurseryModel.numberOfPlaces.toString()),
InfoText(
label: 'Liczba zajętych miejsc',
value: nurseryModel.numberOfPlacesTaken.toString()),
InfoText(
label: 'Podstawowa opłata miesięczna',
value: nurseryModel.monthlyFee),
InfoText(
label: 'Podstawowa opłata godzinowa',
value: nurseryModel.hourlyFee),
InfoText(
label: 'Opłata za wyżywienie - dzienna',
value: nurseryModel.alimentationDailyFee),
InfoText(
label: 'Opłata za wyżywienie - miesięczna',
value: nurseryModel.alimentationMonthlyFee),
InfoText(label: 'Zniżki', value: nurseryModel.discounts),
InfoText(
label: 'Dostowanie do potrzeb dzieci niepełnosprawnych',
value: nurseryModel.specialTreatment ? 'Tak' : 'Nie'),
nurseryModel.workingHours.isNotEmpty
? const Text(
"Godziny otwarcia:",
style: TextStyle(fontWeight: FontWeight.bold),
)
: Container(),
InfoText(
label: " Poniedziałek",
value: nurseryModel.workingHours['Poniedziałek']),
InfoText(
label: " Wtorek",
value: nurseryModel.workingHours['Wtorek']),
InfoText(
label: " Środa", value: nurseryModel.workingHours['Środa']),
InfoText(
label: " Czwartek",
value: nurseryModel.workingHours['Czwartek']),
InfoText(
label: " Piątek",
value: nurseryModel.workingHours['Piątek']),
InfoText(
label: " Sobota",
value: nurseryModel.workingHours['Sobota']),
InfoText(
label: " Niedziela",
value: nurseryModel.workingHours['Niedziela']),
InfoText(
label: "Podmiot prowadzący - nazwa",
value: nurseryModel.operatingEntityName),
InfoText(
label: "Podmiot prowadzący - adres",
value: nurseryModel.operatingEntityAddress),
InfoText(
label: "Podmiot prowadzący - NIP",
value: nurseryModel.operatingEntityNIP != null
? nurseryModel.operatingEntityNIP!.split('.')[0]
: null),
InfoText(
label: "Podmiot prowadzący - REGON",
value: nurseryModel.operatingEntityRegon),
InfoText(
label: "Podmiot prowadzący - numer pozycji rejestru",
value: nurseryModel.operatingEntityRegistryNumber),
const SizedBox(height: 8),
Center(
child: !bookmarks.contains(nurseryModel)
? ElevatedButton.icon(
onPressed: () {
ref
.read(bookmarksControllerProvider.notifier)
.append(nurseryModel);
Navigator.pop(context);
},
icon: const Icon(Icons.bookmark_add),
label: const Text('Dodaj do zakładek'))
: ElevatedButton.icon(
onPressed: () {
ref
.read(bookmarksControllerProvider.notifier)
.remove(nurseryModel);
Navigator.pop(context);
},
icon: const Icon(Icons.remove_circle),
label: const Text('Usuń z zakładek')),
)
],
),
));
}
}
As you can see, this view depends on the state of another feature - bookmarks - as we display a button for adding bookmarks. When creating a real application, it would be worth considering structuring features in a way that they are not dependent on each other. However, it’s not always possible, and in the case of my application, it’s acceptable since it is straightforward.
Let’s take a look at the controller. It holds a state that is a tuple, with coordinates for centering the map and a list of nurseries fetched from the database or an empty list. Initially, the first value contains coordinates appropriate for the borders of Poland. Here, we use the AsyncValue guard, which allows us to handle asynchronous code more efficiently than using try-catch.
@Riverpod(keepAlive: true)
class MapController extends _$MapController {
@override
FutureOr<Tuple2<LatLngBounds, List>> build() {
return Tuple2(
LatLngBounds(
const LatLng(54.8396, 14.1295),
const LatLng(49.0023, 24.1458),
),
[],
);
}
Future<void> findBoundingBox(String address) async {
final NominatimAPI nominatimAPI = ref.read(nominatimAPIProvider);
final FirestoreAPI firestoreAPI = ref.read(firestoreAPIProvider);
state = const AsyncLoading();
state = await AsyncValue.guard(() async {
final res = await nominatimAPI.search(address);
await ref.read(analyticsProvider).logEvent(
name: 'search',
parameters: {'input': address, 'lat': res.lat, 'lon': res.lon});
final bbox = calculateBoundingBox(res.lat, res.lon, 40);
final res_2 = await firestoreAPI.getData(GeoFirePoint(res.lat, res.lon));
return Tuple2(
bbox,
res_2,
);
});
}
}
I’m using keepAlive because I don’t want the search results to disappear when the user switches views in the application. The controller is also using the calculateBoundingBox function, which is a simple mathematical function for determining the bounding box, as found on the internet.
LatLngBounds calculateBoundingBox(double lat, double lng, double distanceKm) {
const double earthRadiusKm = 6371.0;
double latRad = radians(lat);
double latDelta = distanceKm / earthRadiusKm;
double lngDelta = distanceKm / (earthRadiusKm * cos(latRad));
double latMin = lat - latDelta;
double latMax = lat + latDelta;
double lngMin = lng - lngDelta;
double lngMax = lng + lngDelta;
return LatLngBounds(LatLng(latMin, lngMin), LatLng(latMax, lngMax));
}
In the controller method, we also log a custom event to Firebase called “search.” It has user-input as one of its parameters, along with latitude and longitude for that address.
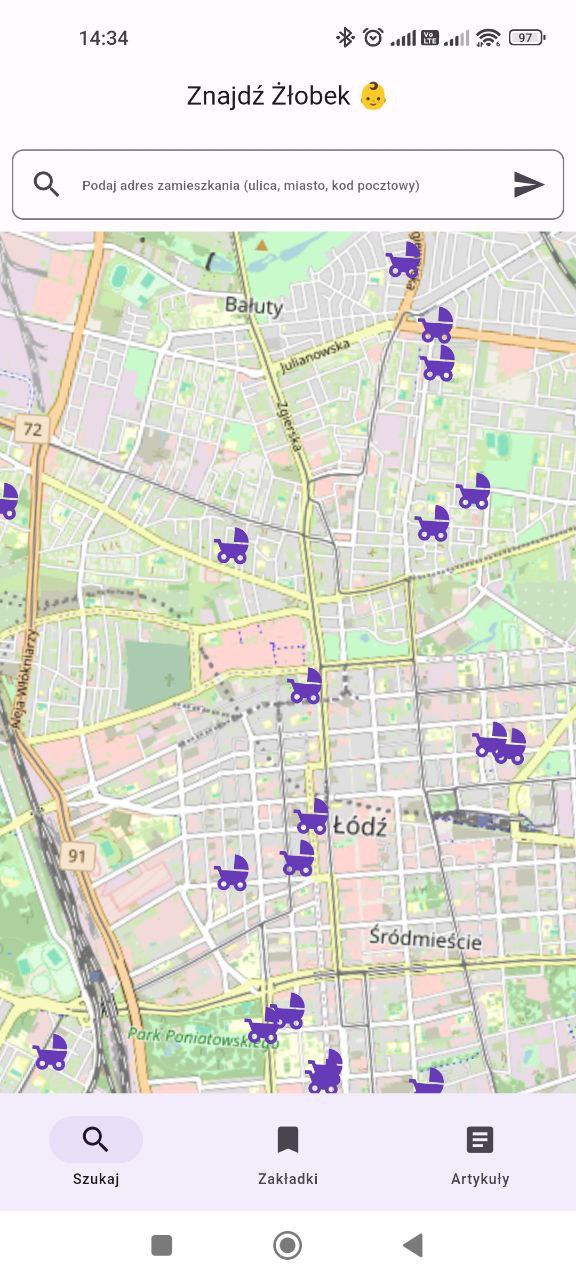

Bookmarks view
The bookmarks view is a simple list of tiles with the name and location of the daycare. After clicking, the user is redirected to a view with details. If the bookmarks list is empty, the application displays a message indicating there are no bookmarks.
class BookmarksView extends ConsumerWidget {
const BookmarksView({super.key});
@override
Widget build(BuildContext context, WidgetRef ref) {
final List bookmarksList = ref.watch(bookmarksControllerProvider);
return bookmarksList.isNotEmpty
? ListView.builder(
itemCount: bookmarksList.length,
itemBuilder: (context, index) {
return Dismissible(
key: Key(bookmarksList[index].id),
onDismissed: (direction) {
ref
.read(bookmarksControllerProvider.notifier)
.remove(bookmarksList[index]);
},
background: Container(color: Colors.deepPurple),
child: ListTile(
title: Text(bookmarksList[index].name),
subtitle: Text(bookmarksList[index].institutionLocation),
leading: const Icon(Icons.child_friendly),
onTap: () {
Navigator.push(
context,
MaterialPageRoute(
builder: (BuildContext context) => NurseryView(
nurseryModel: bookmarksList[index],
)),
);
},
),
);
})
: Center(
child: Column(
mainAxisAlignment: MainAxisAlignment.center,
children: [
Image.network(
"https://emojiisland.com/cdn/shop/products/5_large.png?v=1571606116",
width: 100,
height: 100,
),
const SizedBox(
height: 20,
),
const Text('Nie masz jeszcze żadnych zakładek!'),
],
),
);
}
}
The bookmarks controller contains a list of bookmarks in its state. It has two methods, append and remove, to perform these operations on the list and refresh its state. The methods also log events add_bookmark and remove_bookmark containing daycare information - name and id - in their parameters.
@riverpod
class BookmarksController extends _$BookmarksController {
@override
List<NurseryModel?> build() {
final List<NurseryModel>? bookmarks =
ref.read(hiveAPIProvider).getBookmarks();
return bookmarks ?? [];
}
void append(NurseryModel nurseryModel) async {
HiveAPI hiveAPI = ref.read(hiveAPIProvider);
hiveAPI.addBookmark(nurseryModel);
state = hiveAPI.getBookmarks() ?? [];
try {
await ref.read(analyticsProvider).logEvent(
name: 'add_bookmark',
parameters: {
'nursery_id': nurseryModel.id,
'nursery_name': nurseryModel.name
});
} catch (e, st) {
debugPrint('debug: $e $st');
}
}
void remove(NurseryModel nurseryModel) async {
HiveAPI hiveAPI = ref.read(hiveAPIProvider);
hiveAPI.removeBookmark(nurseryModel.id!);
state = hiveAPI.getBookmarks() ?? [];
try {
await ref.read(analyticsProvider).logEvent(
name: 'remove_bookmark',
parameters: {
'nursery_id': nurseryModel.id,
'nursery_name': nurseryModel.name
});
} catch (e, st) {
debugPrint('debug: $e $st');
}
}
}
Normally, logging errors should be done in a more professional manner than using debugPrint. For example, you could log errors to Crashlytics with Firebase.

Articles view
The articles view is created in the most uncultured way in this application. I generated a few short entries using ChatGPT and store them in the application’s assets. Professionally, it would be better to create a CMS-like system to manage articles in real-time without the need to rebuild the application. The articles view is a simple list of cards, with a placeholder instead of an image. After clicking on a card, the user is redirected to the article view, and their read articles count is logged into Firebase as a user property. I also log an enter_article event with the article name in its parameters.
class ArticleCard extends ConsumerWidget {
final String article;
final String title;
final String subtitle;
const ArticleCard({
Key? key,
required this.article,
required this.title,
required this.subtitle,
}) : super(key: key);
@override
Widget build(BuildContext context, WidgetRef ref) {
return GestureDetector(
onTap: () async {
Navigator.push(
context,
MaterialPageRoute(
builder: (BuildContext context) => ArticleView(article: article),
),
);
try {
await ref
.read(analyticsProvider)
.logEvent(name: 'enter_article', parameters: {'title': title});
} catch (e, st) {
debugPrint('debug: $e $st');
}
try {
HiveAPI hiveAPI = ref.read(hiveAPIProvider);
int currentArticleEntriesCount = hiveAPI.getArticleEntriesProperty();
await ref.read(analyticsProvider).setUserProperty(
name: 'articleEntries',
value: (currentArticleEntriesCount + 1).toString());
hiveAPI.incrementArticleEntriesProperty(currentArticleEntriesCount);
} catch (e, st) {
debugPrint('debug: $e $st');
}
},
child: Card(
shape: RoundedRectangleBorder(borderRadius: BorderRadius.circular(8)),
child: IntrinsicHeight(
child: Column(
children: [
Padding(
padding: const EdgeInsets.all(8.0),
child: Text(
title,
style: const TextStyle(
fontWeight: FontWeight.bold, fontSize: 16),
textAlign: TextAlign.center,
),
),
ClipRRect(
borderRadius: BorderRadius.circular(8),
child: const Image(
image: NetworkImage(
'https://developers.elementor.com/docs/assets/img/elementor-placeholder-image.png'),
height: 200,
width: double.infinity,
fit: BoxFit.cover,
),
),
Padding(
padding: const EdgeInsets.all(8.0),
child: Text(subtitle, style: const TextStyle(fontSize: 12)),
)
],
),
),
),
);
}
}
The code for the articles list view looks as follows.
class ArticlesView extends StatelessWidget {
const ArticlesView({Key? key}) : super(key: key);
@override
Widget build(BuildContext context) {
List<Map> articles = [
{
"article": "przygotowanie.md",
"title": "Przygotowanie dziecka do żłobka",
"subtitle":
"Omówienie strategii i porad dotyczących przygotowania malucha na nowe doświadczenie, jakim jest pobyt w żłobku"
},
{
"article": "wybor.md",
"title": "Wybór odpowiedniego żłobka",
"subtitle":
"Wskazówki dotyczące wyboru instytucji, analiza różnych opcji, kryteria, na które warto zwrócić uwagę"
},
{
"article": "adaptacja.md",
"title": "Adaptacja dziecka do nowego środowiska",
"subtitle":
"Porady dla rodziców dotyczące ułatwiania dziecku adaptacji w nowym otoczeniu, budowania zaufania do personelu i innych dzieci"
},
{
"article": "komunikacja.md",
"title": "Komunikacja z personelem żłobka",
"subtitle":
"Jak utrzymywać regularny kontakt z opiekunami dziecka, jak zadawać pytania i wyrażać swoje oczekiwania"
},
{
"article": "korzysci.md",
"title": "Korzyści dla dziecka z pobytu w żłobku:",
"subtitle":
"Omówienie społecznych, emocjonalnych i rozwojowych korzyści wynikających z uczestnictwa dziecka w żłobku"
},
{
"article": "wspieranie.md",
"title": "Wspieranie rozwoju społecznego dziecka",
"subtitle":
"Jak rozwijać umiejętności społeczne malucha poprzez interakcję z rówieśnikami i opiekunami"
},
{
"article": "mowa.md",
"title": "Żłobek a rozwój mowy",
"subtitle":
"Jak pobyt w żłobku może wpływać na rozwój komunikacyjny dziecka i jak rodzice mogą to wspierać w domu"
},
];
return ListView.builder(
itemCount: articles.length,
itemBuilder: ((context, index) {
return ArticleCard(
article: articles[index]["article"],
title: articles[index]["title"],
subtitle: articles[index]['subtitle']);
}));
}
}
And the code drawing the single article view looks like this:
class ArticleView extends StatelessWidget {
final String article;
const ArticleView({super.key, required this.article});
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(
title: const Text(
'Artykuł 📰',
),
centerTitle: true,
),
body: FutureBuilder(
future: rootBundle.loadString("assets/articles/$article"),
builder: (BuildContext context, AsyncSnapshot<String> snapshot) {
if (snapshot.hasData) {
return Markdown(data: snapshot.data!);
}
return const Center(
child: CircularProgressIndicator(),
);
}),
);
}
}


Analytics
If Firebase integration with BigQuery is enabled, you can analyze raw data about events occurring in a mobile or web application using SQL. This allows for the creation of more customized or complex analyses than what can be achieved using the Firebase or Google Analytics panels. BigQuery is part of Google Cloud, and while it’s not a free service, in the free Firebase plan, you get access to the sandbox mode and can process up to 10GB of data without any additional charges. In this section, I won’t show anything advanced; after all, the application logs only 4 events and one user property. Besides, there’s no way to generate significant traffic. I’d like to show just a few typical query patterns, syntactic tricks, or pieces of information that can be utilized in a serious, production-level data analysis.
An important piece of information is that the data coming from Firebase is partitioned based on days. It’s worth keeping this in mind, as it helps save costs on queries. However, it’s essential to search for data using the pseudo-column _table_suffix instead of a field like event_date. Using the latter would search the entire dataset rather than the expected range of data. For example, to query the number of active users in a specific period, broken down by device type, you can use the following approach:
SELECT
device.category,
COUNT(DISTINCT user_pseudo_id) AS active_users_count
FROM
`znajdz-zlobek.analytics_1111111.events_*`
WHERE
event_name = 'user_engagement'
AND _table_suffix BETWEEN '20240120'
AND '20240124'
GROUP BY 1
ORDER BY 2 DESC
The user_engagement event is automatically collected if the app is in the foreground for at least a second or if the website is in focus for the same duration. This allows excluding users who received a notification, registered the corresponding event, but did not open the application. Typically, we are interested in users who are actively using the application.
Since user_engagement records the time of user engagement—being sent when the user performs an action indicating closing the application or losing engagement, such as prolonged inactivity, switching to another page or screen, or encountering an error—you can calculate the average and total engagement time per device type.
SELECT
device.category,
ROUND(AVG((
SELECT
value.int_value
FROM
UNNEST(event_params)
WHERE
KEY = 'engagement_time_msec')) / 1000, 2) AS avg_engagement_time,
ROUND(SUM((
SELECT
value.int_value
FROM
UNNEST(event_params)
WHERE
KEY = 'engagement_time_msec')) / 1000, 2) AS total_engagement_time,
FROM
`znajdz-zlobek.analytics_1111111.events_*`
WHERE
event_name = 'user_engagement'
AND _table_suffix BETWEEN '20240120'
AND '20240124'
GROUP BY
1
ORDER BY
2 DESC
Here, you can notice the use of the UNNEST operator. BigQuery supports nested data structures, and this operator allows you to flatten them. Typically, event parameters and user properties, such as those shown during the construction of the application, are stored in these nested structures. By using the enter_article event, you can check, for example, which articles were most frequently visited during a specific period.
SELECT
(
SELECT
value.string_value
FROM
UNNEST(event_params)
WHERE
KEY = 'title') AS article_title,
COUNT(event_name) AS entries_count
FROM
`znajdz-zlobek.analytics_1111111.events_*`
WHERE
_table_suffix BETWEEN '20240120'
AND '20240124'
AND event_name = 'enter_article'
GROUP BY 1
ORDER BY 2 DESC
Based on this information, you could establish the display order of articles in the application or write future articles in a manner similar to those most frequently visited. You could also identify which articles are visited the least. This might be because they are, for example, at the bottom of the list, and perhaps it would be worthwhile to encourage users to access them in a different way, such as sending notifications or displaying a bottom sheet. We can also try to examine the distribution of the number of visited articles by users in a given period. We’ll do this using percentiles, dividing the dataset into five classic groups. This metric is not the best for this, it’s just an example.
SELECT
percentiles[offset(10)] AS p10,
percentiles[offset(25)] AS p25,
percentiles[offset(50)] AS p50,
percentiles[offset(75)] AS p75,
percentiles[offset(90)] AS p90,
FROM (
SELECT
APPROX_QUANTILES(entries, 100) AS percentiles
FROM (
SELECT
user_pseudo_id,
MAX((
SELECT
value.string_value
FROM
UNNEST(user_properties)
WHERE
KEY = 'articleEntries')) AS entries
FROM
`znajdz-zlobek.analytics_1111111.events_*`
WHERE
_table_suffix BETWEEN '20240120'
AND '20240124'
GROUP BY
1 ) )
Based on it, you could determine, for example, how many articles the top 10% most engaged users access. Using this information, you could change the application’s behavior for a user once they exceed this threshold, treating them differently in some way. A nested query with a max per ID is here because BigQuery doesn’t allow using aggregations of aggregations.
Personally, I also enjoy using Common Table Expressions (CTEs). This allows for a pleasant optimization of query structure, making them more readable, especially when the code grows to hundreds of lines. CTEs can be helpful, for instance, if we want to find out how many users performed a search operation - search event and added a bookmark - add_bookmark event.
WITH
searchers AS (
SELECT
user_pseudo_id
FROM
`znajdz-zlobek.analytics_1111111.events_*`
WHERE
_table_suffix BETWEEN '20240120'
AND '20240124'
AND event_name = 'search' )
SELECT
COUNT(DISTINCT user_pseudo_id) AS users_count,
FROM
`znajdz-zlobek.analytics_1111111.events_*`
WHERE
_table_suffix BETWEEN '20240120'
AND '20240124'
AND event_name = 'add_bookmark'
AND user_pseudo_id IN (
SELECT
*
FROM
searchers)
Of course, this isn’t particularly valuable information, especially since the events are interdependent – without a search, it’s challenging to add a bookmark. But it just illustrates simple query patterns here. I most often use CTEs when analyzing various A/B tests to slightly expand the results provided in the console, incorporating additional factors into test groups that were not considered in the baseline test. This allows for a deeper dive, especially when results seem strange or even unrealistic. An important point to note is that despite theoretically scanning the dataset twice in one query, the cost of the query is not doubled when using CTEs (assuming, of course, that you are querying the same partition set).
A cool feature in BigQuery is the ability to create custom functions not only in the dedicated procedural language but also in regular JavaScript. This allows you to add a function that facilitates comparing string representations of versions, which is often important. Let’s check, for example, how many users have used a version greater than or equal to 1.0.0.
CREATE TEMP FUNCTION
compareVersions(v1 STRING,
v2 STRING)
RETURNS INT64
LANGUAGE js AS r"""
var vnum1 = 0, vnum2 = 0;
for (var i = 0, j = 0; (i < v1.length || j < v2.length);) {
while (i < v1.length && v1[i] != '.') {
vnum1 = vnum1 * 10 + (v1[i] - '0');
i++;
}
while (j < v2.length && v2[j] != '.') {
vnum2 = vnum2 * 10 + (v2[j] - '0');
j++;
}
if (vnum1 > vnum2)
return 1;
if (vnum2 > vnum1)
return -1;
vnum1 = vnum2 = 0;
i++;
j++;
}
return 0;
""";
SELECT
COUNT(DISTINCT user_pseudo_id)
FROM
`znajdz-zlobek.analytics_1111111.events_*`
WHERE
_table_suffix BETWEEN '20240120'
AND '20240124' AND
compareVersions(app_info.version,
'1.0.0') IN (0,
1)
This is, of course, a very basic knowledge, just a few simple queries. SQL is a powerful language that allows for much more complex analyses.
Conclusion
In the post, I presented a very simple ETL process using Python, the process of creating a simple application using Flutter, and basic analytics in BigQuery using SQL. It’s all straightforward, but I’m satisfied with the material presented. I believe the most crucial takeaway is to never forget about analytics. When creating an application, it’s essential to plan for analytics and ensure that as the complexity of the product grows, analytical processes are expanded accordingly. See you in the next post!