F1 Analytics - a simple web app powered by data
Introduction
My first python project after the simple and local console ones was the F1 Analytics - a simple site for Formula 1 historical statistics overview. The project was conducted around one and a half years ago, so it is pretty old and I think it needs a rework. There are various arguments for why it should be upgraded. The site is hosted on Heroku - the third-party platform. The free tier is not so generous, for example, the site falls asleep after 30 minutes without the traffic. I have the private space, so I can host it on my own. The data is stored in Google BigQuery. It is an awesome warehouse, but for such a small database it has more risks than benefits. In one word - it is overkill. I can store the data on my own also. The site is connected directly to the database which also has a lot of drawbacks. Now the data processing will be part of the pipeline and the site will fetch already transformed data from the handy API. The front end also needs to be updated. There were some changes in Formula 1, for example, the points from sprint should be counted also. The project is also quite old and was one of my first coding challenges, so the code is pretty messy. The last thing is just vanity. I do not have any idea for the next project and blog post. Tbh I am quite tired and already waiting for the serious holidays. I am also currently spending a lot of time improving my theoretical knowledge, for example by reading things (I would recommend this amazing book). Refactoring the existing project seems like a fantastic idea for the ’lazy project'.
General architecture
The Ergast provides provide the data in the API and also a database images or CSV files form. This project uses files mainly because I have already created the project about the Ergast API. The second thing is that Ergast provides the data mostly for analytical purposes. It would be quite unfair to use their servers for my web app. To obtain the data files and store them in the SQLite3 database the bash script is running every 12 AM/PM (scheduled with CRON). It also checks if the data is updated, if so it sends the POST request to the webhook, which transforms the required data and upserts it into MongoDB. The data in the optimal form is served via API and accessed by a web app created with Dash. The WSGI Server used is the Gunicorn with 2 workers and 2 threads. The whole project is containerized using Docker with docker-compose. The web server is Caddy, but it won’t be shown in the repository, because the project should be ready to reproduce locally. You can take a look at the architecture in the picture below:

At the end of the project the directory tree should look like this:
f1_analytics
| .gitignore
| .env
| docker-compose.yaml
| mongo-init.sh
|___etl
| |___cron_part
| | | checker.sh
| | | entrypoint,sh
| | | cronjobs
| | | Dockerfile
| |___webhook_part
| | | webhook.py
| | | transform_load.py
| | | utils.py
| | | config.py
| | | requirements.txt
| | | Dockerfile
|___app
| |___api
| | | server.py
| | | config.py
| | | gunicorn_config.py
| | | entrypoint.sh
| | | requirements.txt
| | | Dockerfile
| |___web
| | | app.py
| | | index.py
| | | components.py
| | | gunicorn_config.py
| | | entrypoint.sh
| | | requirements.txt
| | | Dockerfile
| | |___tabs
| | | | drivers.py
| | | | incidents.py
| | | | races.py
| | | | seasons.py
| | | | sidepanel.py
Data Pipeline
Cron part
Shell script
For the first part of the project, I decided to use shell scripting. I do not think it is the best choice, I could code it in python much faster and better. However, I didn’t show that I can write the scripts in bash on this blog yet. The first thing to do obtaining the page with curl and find the last update date with grep:
#!/bin/bash
# get the website with database images
URL=$(curl -sS 'http://ergast.com/mrd/db/')
# find the last update date with regex
CURRENT_DATE=$(echo "$URL" | grep -o -P '(?<=last updated on: ).*?(?=</p>)')
-o flag for showing matches only and -P flag for Perl regular expressions usage.
The obtained variable should be compared with the last saved date to tell the script to know if it should perform actions. For the initial load it doesn’t exist, so let’s create it in the condition block, then read it to the variable:
# condition creating a txt just for the initial load
if [ ! -f ./date.txt ]; then
echo 'initial load'> ./date.txt
fi
# read last saved date
LAST_DATE=$(cat ./date.txt)
The whole action starts now. SQLite utility cannot a database in the non-existing directory or I do not know how to do this, so before the fireworks, it should be created:
# create a directory for database (and docker volume) if not exists
mkdir -p db
Everything is ready to create a condition block that will perform a bunch of tasks if the data on the Ergast website is updated. The first thing is downloading the archive, decompressing it, and removing the zip.
if [ "$CURRENT_DATE" != "$LAST_DATE" ]; then
curl -sS 'http://ergast.com/downloads/f1db_csv.zip' --output f1db_csv.zip && unzip -qq -o f1db_csv.zip -d ./csvs &&
rm f1db_csv.zip && # download the archive, decompress it and remove zip
-sS and -qqflags are used for silent modes, -o for overwriting the files without prompting.
The next thing is inserting the CSVs into the SQLite database. It can be done in the simple for loop:
for f in ./csvs/*.csv;
do
sqlite3 ./db/f1db.db ".mode csv" ".import $f $(basename $f .csv)" ".exit"
done &&
The CSV files can be recursively removed:
rm -r ./csvs && # remove directory with csvs
The date in the text file should be replaced:
echo "$CURRENT_DATE" > ./date.txt && # replace the date stored in the text file
Now, it is time to send a POST request to the webhook service, also with the curl:
curl -sS -X POST -H "Content-Type: application/json" -d '{"message": "ready to serve"}' http://f1analytics-webhook:5010/webhook && # send a post request to the web hook
The URL contains the name of the docker container with its port.
At the end of the condition block let’s log the update or no change:
echo "$(date "+%m-%d-%Y %T") : Data updated" # log the update message
else
echo "$(date "+%m-%d-%Y %T") : No change" # log the no change message
fi
Cronjobs
Quick part, just set up the cron to run every 12 AM/PM and log output to the file.
0 0,12 * * * cd /etl && sh checker.sh >> log.txt 2>&1
Entrypoint
Here is a little cheat. I would like to run the script immediately, so I will execute it and then run the cron:
#!/bin/bash
sh /etl/checker.sh >> log.txt 2>&1 && cron -f
-f flag for running the cron in the foreground. Normally it would run in the background, which could be dangerous (for example the failure of the process would be unnoticed).
Dockerfile
Creating the Dockerfile for the one cron scheduled shell script is not the hardest task. The distro image I usually use is the debian:bullseye-slim, it meets my needs perfectly. The following Dockerfile installs curl cron unzip and sqlite3 packages because they are used in the shell script. Both .sh files are copied and granted with executable permission. Next, the cronjobs are copied into the cron.d directory, granted with the proper permissions and added to the crontab. Entrypoint just executes the previously defined command.
FROM debian:bullseye-slim
RUN apt-get update && apt-get install curl cron unzip sqlite3 -y
WORKDIR /etl
COPY checker.sh entrypoint.sh ./
RUN chmod +x checker.sh entrypoint.sh
COPY cronjobs /etc/cron.d/cronjobs
RUN chmod 0644 /etc/cron.d/cronjobs
RUN crontab /etc/cron.d/cronjobs
ENTRYPOINT ["sh", "entrypoint.sh"]
Webhook part
Webhook
Webhook is an endpoint that is triggered when some event occurs. In the data world, webhooks are the easiest form of the subscription model. In my project, the webhook gets notified when the new data is successfully loaded into the SQLite database. It makes transformations using SQL and loads the data in the ready-to-serve for web app form into MongoDB.
import pymongo
from flask import Flask, request
from utils import mongo_config, bulk_insert
from data_wrangle import (
get_drivers_performance,
get_drivers_season_data,
get_constructors_season_data,
get_races_data,
get_status_data,
get_seasons,
get_drivers,
)
app = Flask(__name__)
@app.route("/webhook", methods=["POST"])
def webhook():
if request.json["message"] == "ready to serve":
# get and insert seasons data
get_seasons()
# get and insert drivers data
get_drivers()
# get and insert drivers performance data
get_drivers_performance()
# get and insert drivers seasons data
get_drivers_season_data()
# get and insert constructors seasons data
get_constructors_season_data()
# get and insert races data
get_races_data()
# get and insert incidents data
get_status_data()
return "OK\n"
app.run(host="0.0.0.0", port=5010)
The only thing to notice here is specifying the POST method in the route. All of the functions will be described in the rest of this part.
Transform and load
The utils file contains the functions for connecting with databases and upsert into MongoDB collection (update if exists else insert):
import sqlite3
import pymongo
from config import mongo_access
# set connection with sqlite db
def connect_db():
return sqlite3.connect(r"./db/f1db.db")
# configure mongodb client
def mongo_config():
client = pymongo.MongoClient(mongo_access)
db = client[db_name]
return db
# helper for repeatable inserting
def mongo_upsert(data, collection):
data = dict(data)
collection.update_one({"_id": data["_id"]}, {"$set": data}, upsert=True)
Data wrangling for this project contains just simple SQL aggregation. Then I am loading the obtained data into MongoDB in the loop using previously created function. Doing this in this step means that the data is transformed once and the web app will just fetch already transformed data. Previously, processing was done on the application side, which was a terrible design.
import sqlite3
from utils import connect_db, mongo_upsert, mongo_config
# Construct the data for "Grand Prix" page and load it into the races collection
def get_races_data():
conn = connect_db()
db = mongo_config()
conn.row_factory = sqlite3.Row
cur = conn.cursor()
cur.execute(
"""
SELECT ra.raceId AS _id, ra.year AS Season, ra.date AS Date, ra.name AS 'Grand Prix',
d.forename || d.surname AS Winner, c.name AS Constructor,
ct.name AS Circuit, ct.lat, ct.lng, ct.location AS Location
FROM drivers AS d
LEFT JOIN results AS r
ON d.driverId = r.driverId
LEFT JOIN races AS ra
ON r.raceId = ra.raceId
LEFT JOIN constructors AS c
ON r.constructorId = c.constructorId
LEFT JOIN circuits AS ct
ON ra.circuitId = ct.circuitId
WHERE r.position = 1
ORDER BY ra.date
"""
)
for row in cur:
mongo_upsert(row, db.races)
conn.close()
# Construct the data for "Incidents" page and load it into incidents collection
def get_status_data():
conn = connect_db()
db = mongo_config()
conn.row_factory = sqlite3.Row
cur = conn.cursor()
cur.execute(
"""
SELECT ct.circuitId || ra.year || d.driverId AS _id, ra.year AS Season, ra.date AS Date, ct.name AS Circuit,
d.forename || ' ' || d.surname AS Driver, c.name AS Constructor, st.status AS Incident
FROM drivers AS d
LEFT JOIN results AS r
ON d.driverId = r.driverId
LEFT JOIN races AS ra
ON r.raceId = ra.raceId
LEFT JOIN constructors AS c
ON r.constructorId = c.constructorId
LEFT JOIN circuits AS ct
ON ra.circuitId = ct.circuitId
LEFT JOIN status as st
ON r.statusId = st.statusId
WHERE st.status NOT LIKE '%Lap%' AND st.status != 'Finished'
ORDER BY ra.date
"""
)
for x in cur:
mongo_upsert(x, db.incidents)
conn.close()
# Construct the data for "Drivers" page and load it into drivers_performance collection
def get_drivers_performance():
conn = connect_db()
db = mongo_config()
conn.row_factory = sqlite3.Row
cur = conn.cursor()
cur.execute(
"""
SELECT d.driverId || ra.raceId || ra.year || d.surname AS _id, d.forename || ' ' || d.surname AS Driver, ct.name AS Circuit,
c.name AS Constructor, r.position as Position,
d_st.points AS Points, ra.round AS Round, ra.year AS Season,
r.grid AS Grid
FROM drivers AS d
LEFT JOIN results AS r
ON d.driverId = r.driverId
LEFT JOIN races AS ra
ON r.raceId = ra.RaceId
LEFT JOIN constructors AS c
ON r.constructorId = c.constructorId
LEFT JOIN circuits AS ct
ON ra.circuitId = ct.circuitId
LEFT JOIN driver_standings AS d_st
ON d.driverId = d_st.driverId AND ra.raceId = d_st.raceId
ORDER BY ra.year
"""
)
for x in cur:
mongo_upsert(x, db.drivers_performance)
conn.close()
# Construct the data for "Seasons" page and loat it into drivers_seasons collection
def get_drivers_season_data():
conn = connect_db()
db = mongo_config()
conn.row_factory = sqlite3.Row
cur = conn.cursor()
cur.execute(
"""
WITH podiums AS (
SELECT d.driverId, ra.year,
COUNT(DISTINCT r.raceId) AS Podiums
FROM drivers AS d
LEFT JOIN results AS r
ON d.driverId = r.driverId
LEFT JOIN races AS ra
ON r.raceId = ra.raceId
WHERE r.position IN (1, 2, 3)
GROUP BY 1, 2
)
SELECT d.driverId || ra.year AS _id, d.forename || ' ' || d.surname AS Driver,
d.nationality AS Nationality, ra.year AS Season,
MAX(CAST(d_st.points AS FLOAT)) AS Points,
p.Podiums
FROM drivers AS d
LEFT JOIN driver_standings AS d_st
ON d.driverId = d_st.driverId
LEFT JOIN races AS ra
ON d_st.raceId = ra.raceId
LEFT JOIN podiums AS p
ON d.driverId = p.driverId AND ra.year = p.year
GROUP BY 1, 2, 3, 4
ORDER BY 5 DESC
"""
)
for x in cur:
mongo_upsert(x, db.drivers_seasons)
conn.close()
# Construct the data for "Seasons" page and load it into constructors_seasons collection
def get_constructors_season_data():
conn = connect_db()
db = mongo_config()
conn.row_factory = sqlite3.Row
cur = conn.cursor()
cur.execute(
"""
WITH podiums AS (
SELECT c.constructorId, ra.year,
COUNT(DISTINCT r.raceId) AS Podiums
FROM constructors AS c
LEFT JOIN results AS r
ON c.constructorId = r.constructorId
LEFT JOIN races AS ra
ON r.raceId = ra.raceId
WHERE r.position IN (1, 2, 3)
GROUP BY 1, 2
)
SELECT c.constructorId || ra.year AS _id, c.name AS Constructor,
c.nationality AS Nationality, ra.year AS Season,
MAX(CAST(c_st.points AS FLOAT)) AS Points,
p.Podiums
FROM constructors AS c
LEFT JOIN constructor_standings AS c_st
ON c.constructorId = c_st.constructorId
LEFT JOIN races AS ra
ON c_st.raceId = ra.raceId
LEFT JOIN podiums AS p
ON c.constructorId = p.constructorId AND ra.year = p.year
GROUP BY 1, 2, 3, 4
ORDER BY 5 DESC
"""
)
for x in cur:
mongo_upsert(x, db.constructors_seasons)
conn.close()
# Get max year
def get_seasons():
conn = connect_db()
db = mongo_config()
conn.row_factory = sqlite3.Row
cur = conn.cursor()
cur.execute(
"""
SELECT DISTINCT year AS _id, year AS Season
FROM races
ORDER BY 1 DESC
"""
)
for x in cur:
mongo_upsert(x, db.seasons)
conn.close()
# Get drivers list
def get_drivers():
conn = connect_db()
db = mongo_config()
conn.row_factory = sqlite3.Row
cur = conn.cursor()
cur.execute(
"""
SELECT DISTINCT driverId AS _id, driver FROM (
SELECT driverId, forename || ' ' || surname AS driver
FROM drivers
) AS sub
ORDER BY 2
"""
)
for x in cur:
mongo_upsert(x, db.drivers)
conn.close()
As you can see I am using the sqlite3.Row type. The reason is easier to convert the results to the dictionary for loading into the document-type database.
Dockerfile
Easy peasy step, just running the flask app. I am not using any production server here, because it won’t be ever online and always be responsible for processing one certain request at the specified time.
FROM python:3.10-slim-bullseye
WORKDIR /etl
COPY requirements.txt .
RUN pip install -r requirements.txt
COPY config.py utils.py transform_load.py webhook.py ./
ENTRYPOINT ["python", "webhook.py"]
Web
API
Server
It is time to create an endpoint for every previously created table in MongoDB. Serving the whole table at once wouldn’t be reasonable, tables are quite big. Breaking them by year or driver is a good idea because the dashboards will have such a filter:
from flask import Flask, jsonify
from pymongo import MongoClient
from config import mongo_access
app = Flask(__name__)
client = MongoClient(mongo_access)
db = client[db_name]
# create endpoint for seasons data
@app.route("/api/seasons", methods=["GET"])
def seasons():
table = db.seasons
return jsonify(list(table.find({}, {"_id": False})))
# create endpoint for drivers data
@app.route("/api/drivers", methods=["GET"])
def drivers():
table = db.drivers
return jsonify(list(table.find({}, {"_id": False})))
# create endpoint for drivers seasons data
@app.route("/api/drivers_seasons/<string:season>", methods=["GET"])
def drivers_seasons(season):
table = db.drivers_seasons
return jsonify(list(table.find({"Season": season}, {"_id": False})))
# create endpoint for constructors seasons data
@app.route("/api/constructors_seasons/<string:season>", methods=["GET"])
def constructors_seasons(season):
table = db.constructors_seasons
return jsonify(list(table.find({"Season": season}, {"_id": False})))
# create endpoint for races data
@app.route("/api/races/<string:season>", methods=["GET"])
def races(season):
table = db.races
return jsonify(list(table.find({"Season": season}, {"_id": False})))
# create endpoint for incidents data
@app.route("/api/incidents/<string:season>", methods=["GET"])
def incidents(season):
table = db.incidents
return jsonify(list(table.find({"Season": season}, {"_id": False})))
# create endpoint for drivers performance data
@app.route("/api/drivers_performance/<string:driver>", methods=["GET"])
def drivers_performance(driver):
table = db.drivers_performance
return jsonify(list(table.find({"Driver": driver}, {"_id": False})))
if __name__ == "__main__":
app.run(host="0.0.0.0", port=5011)
As you can see I am ignoring the _id field. It was required to make the aggregation properly in the previous step. Now it would make a mess in the front end step (remember it is created almost two years ago - I do not want to spend a lot of time reconfiguring it).
WSGI
I will run this app in the production environment. That’s why the web part needs WSGI. I can tell that WSGI is required to handle the workload if multiple users are playing with the application. In simple words - the application won’t be extremely slow. You can read more about it here. The first thing to do is to create a config file:
bind = "0.0.0.0:5011"
workers = 2
threads = 2
timeout = 120
Bind parameter is the socket to bind, workers parameter is the number of worker processes for handling requests, threads parameter is the number of worker threads for handling requests, timeout parameter means that workers are silent for more than this many seconds are killed and restarted.
The app can be run with the created config directly from the Dockerfile, but it is always more readable to create the entry point. It is simply one line:
#!/bin/bash
gunicorn --config ./gunicorn_config.py server:app
Dockerfile
Dockerfile is simple as always, the only difference is that the entry point is running the external file:
FROM python:3.10-slim-bullseye
WORKDIR /api
COPY requirements.txt .
RUN pip install -r requirements.txt
COPY config.py server.py gunicorn_config.py entrypoint.sh ./
RUN chmod +x ./entrypoint.sh
ENTRYPOINT ["sh", "entrypoint.sh"]
App
Dash app
I won’t describe the whole frontend part of the application. It is not so small and I created it almost 2 years ago. You can check the code in the repository linked in the conclusion. One thing I would like to mention is the usage of pandas. I can wrap the JSON in the pandas’ data frames with a little cost because it is a Dash framework dependency anyway. It makes life a lot easier because Dash is designed to cooperate with pandas.
WSGI
It is pretty much the same as for the API server. Entrypoint is a bit different. It has a sleep command with 70 seconds value. It is designed for the initial load, so the app won’t be started if the API is not serving any data. It is a very trivial solution and could be done better I think.
#!/bin/bash
sleep 70
gunicorn --config ./gunicorn_config.py index:server
Dockerfile
It is the same like in the API part:
FROM python:3.10-slim-bullseye
WORKDIR /web
COPY requirements.txt .
RUN pip install -r requirements.txt
COPY tabs tabs/
COPY app.py components.py index.py gunicorn_config.py entrypoint.sh ./
RUN chmod +x ./entrypoint.sh
ENTRYPOINT ["sh", "entrypoint.sh"]
Compose
The docker-compose is the hearth of the project:
version: '3.8'
services:
cron:
build: ./etl/cron_part
container_name: f1analytics-cron
volumes:
- sqlite-data:/etl/db
depends_on:
- "webhook"
webhook:
build: ./etl/webhook_part
container_name: f1analytics-webhook
ports:
- 5010:5010
environment:
- MONGO_ACCESS=${MONGO_ACCESS}
- DB_NAME=${DB_NAME}
volumes:
- sqlite-data:/etl/db
depends_on:
- "mongodb"
api:
build: ./app/api
container_name: f1analytics-api
ports:
- 5011:5011
environment:
- MONGO_ACCESS=${MONGO_ACCESS}
- DB_NAME=${DB_NAME}
depends_on:
- "mongodb"
app:
build: ./app/web
container_name: f1analytics-app
ports:
- 5012:5012
depends_on:
- "api"
restart: unless-stopped
mongodb:
image: mongo
container_name: mongodb
environment:
- MONGO_INITDB_ROOT_USERNAME=${ROOT_NAME}
- MONGO_INITDB_ROOT_PASSWORD=${ROOT_PASSWORD}
- DB_NAME=${DB_NAME}
- DB_USER=${DB_USER}
- DB_PASSWORD=${DB_PASSWORD}
ports:
- 27017:27017
volumes:
- mongodb-data:/data/db
- ./mongo-init.sh:/docker-entrypoint-initdb.d/mongo-init.sh
restart: unless-stopped
volumes:
mongodb-data:
sqlite-data:
It builds all of the parts coded previously. It has two volumes - for databases. MongoDB is running first, then webhook and API, then cron and app at the end. Environmental variables are passed from the .env file. As you can see the MongoDB is initiated from the external file:
mongo --eval "db.auth('$MONGO_INITDB_ROOT_USERNAME', '$MONGO_INITDB_ROOT_PASSWORD'); db = db.getSiblingDB('$DB_NAME'); db.createUser({ user: '$DB_USER', pwd: '$DB_PASSWORD', roles: [{ role: 'readWrite', db: '$DB_NAME' }] });"
It creates a new database for the data and a user with reading and writing permissions for this database. The other way for managing MongoDB from external scripts is via javascript, but I prefer shell script, because of the ability to use the environment variables.
Now the project can be run with:
docker-compose up -d
But be careful, the repository is not supposed to be run in production. If you would like to, please take care of the security!
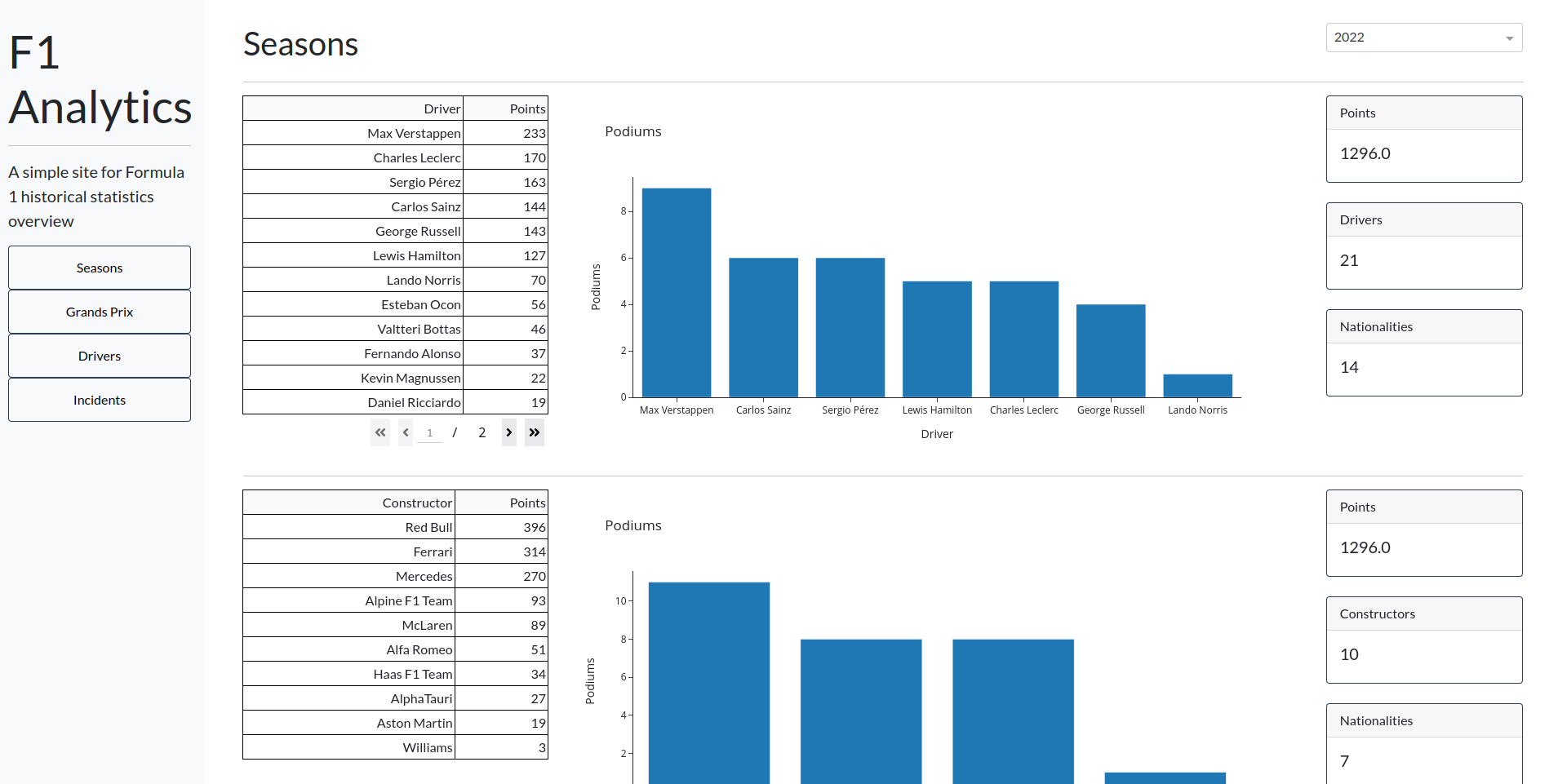
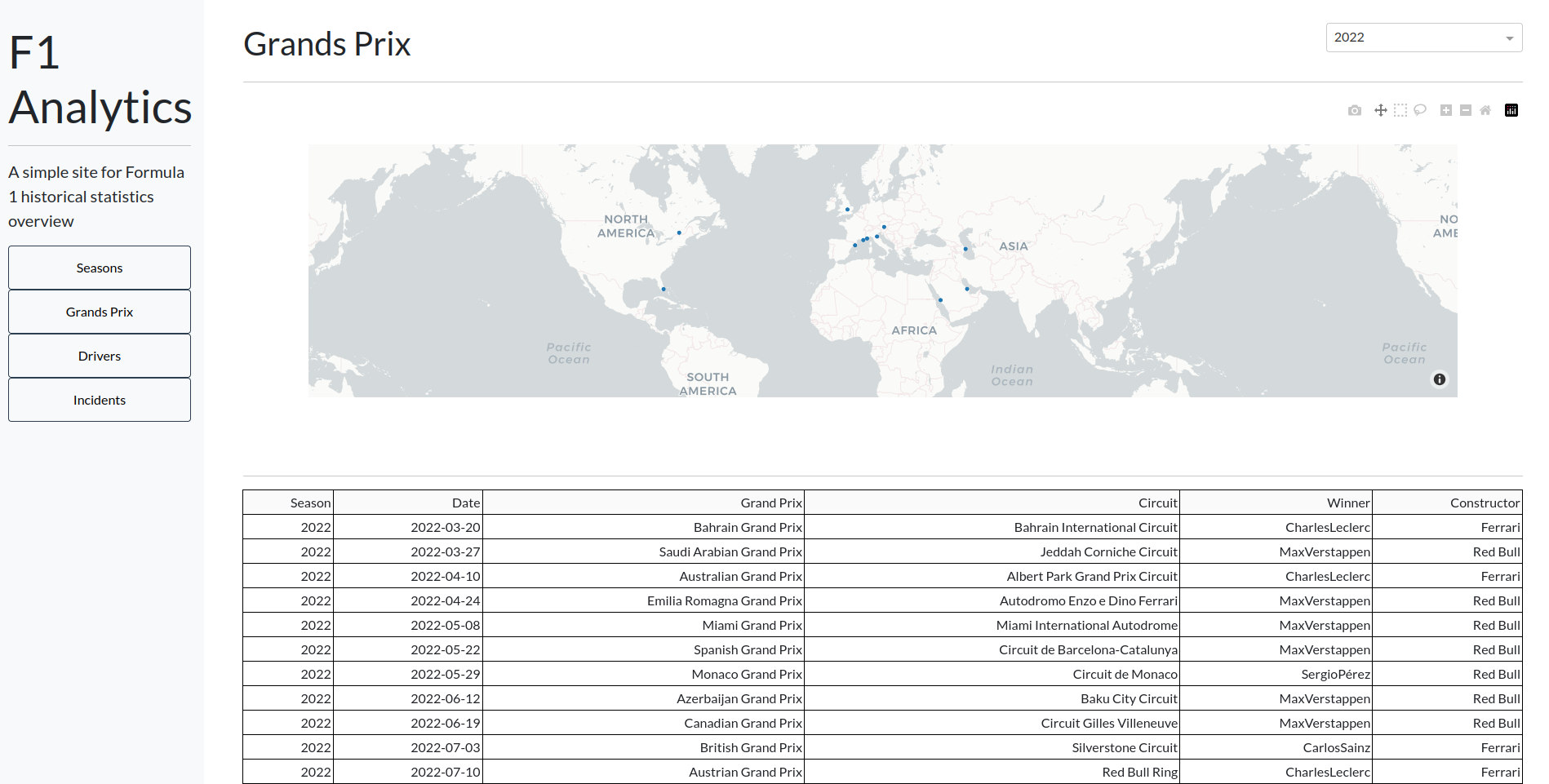
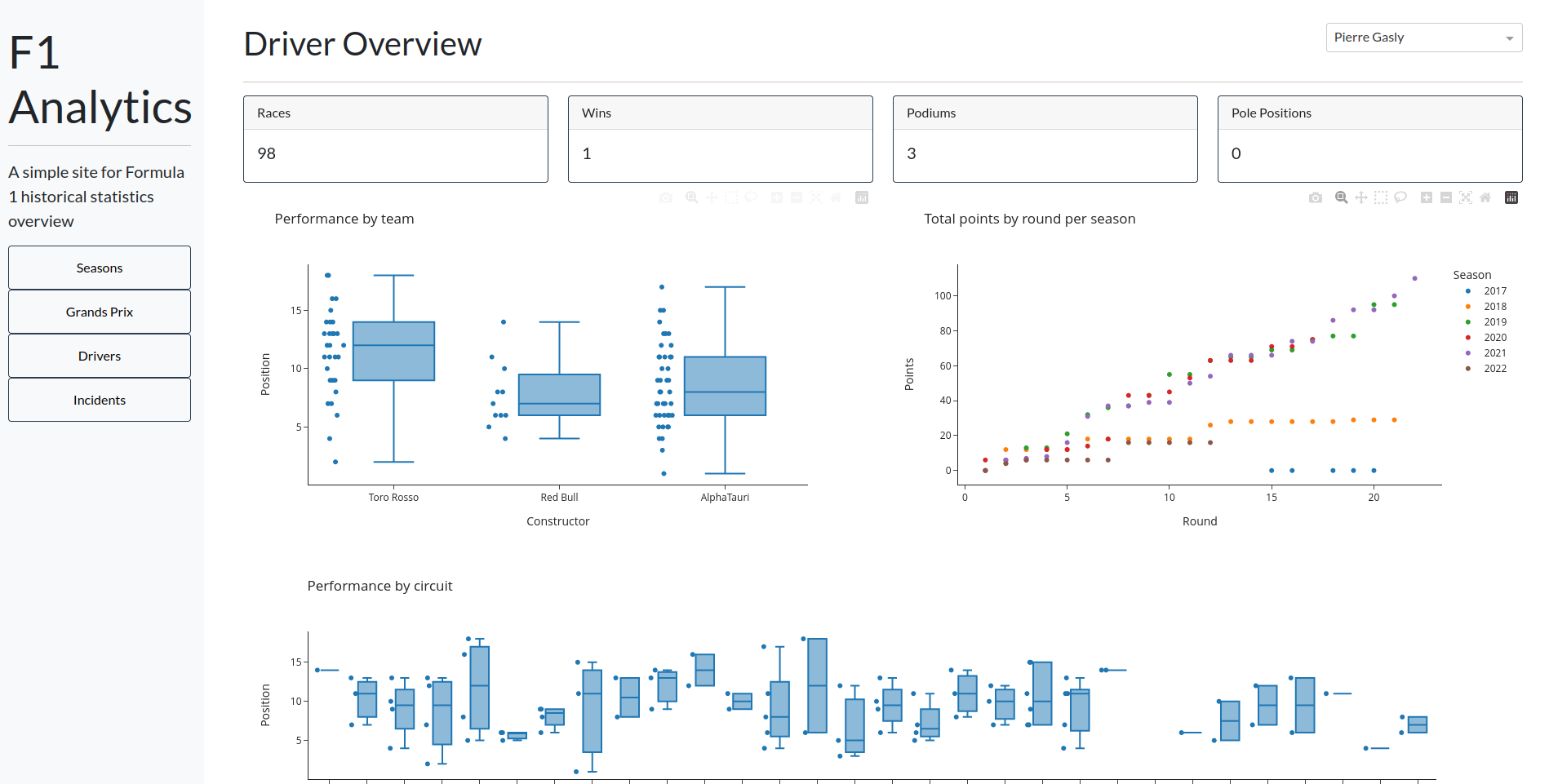
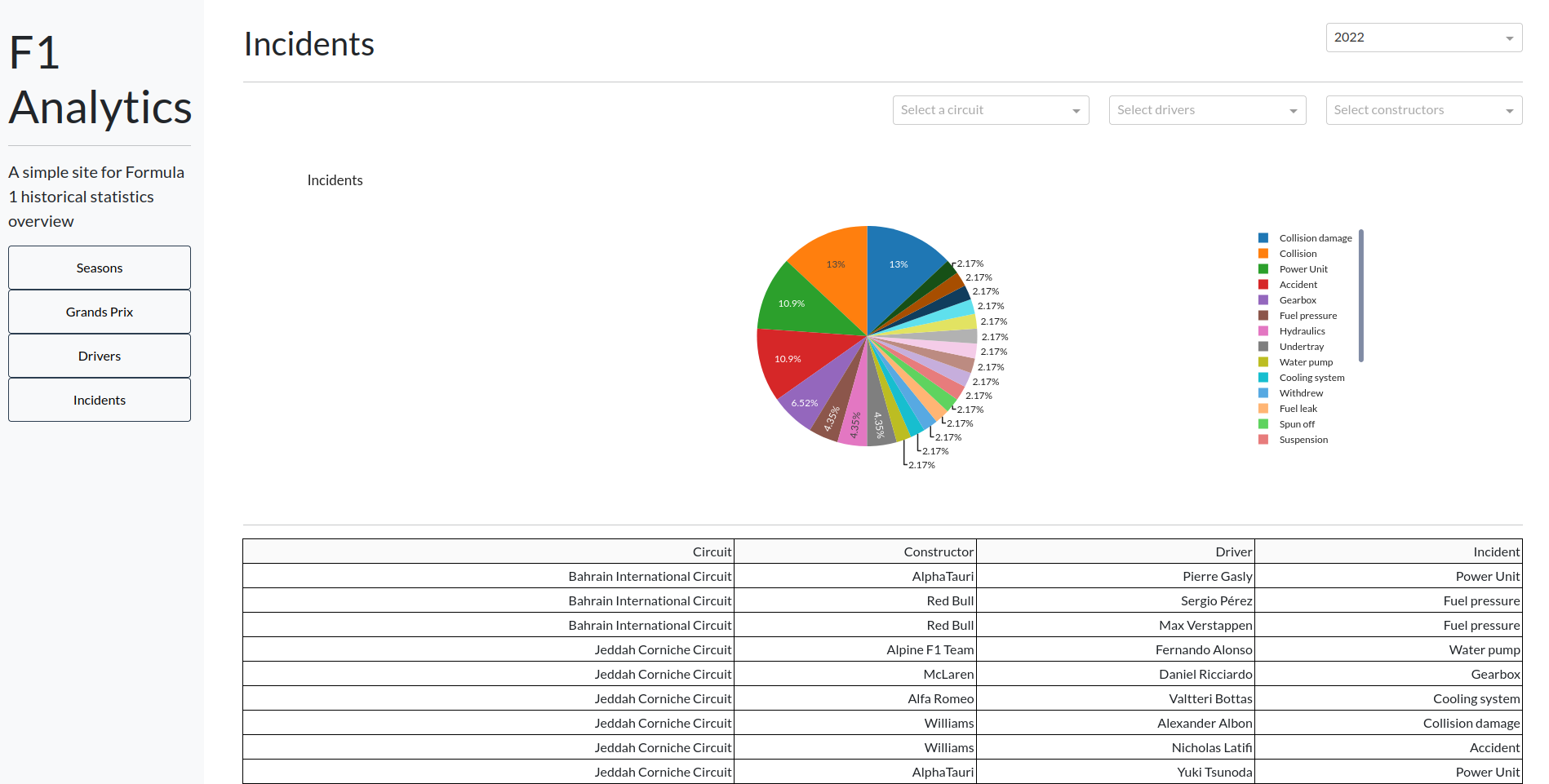
Conclusion
The project was more interesting than I thought. I am happy that I could create it in a few days, including writing a blog post (the hardest thing). You can check the repo here. I plan that the next project will include the streaming tool, probably Apache Kafka. Tbh I would like to create a data engineering project that will contain various tools. Wish me luck! Cya!
References
- https://blog.logrocket.com/receive-webhooks-python-flask-or-django/
- https://lovethepenguin.com/sqlite3-how-to-import-csv-files-to-tables-from-bash-3bca7daedd31
- https://www.airplane.dev/blog/docker-cron-jobs-how-to-run-cron-inside-containers
- https://blog.thesparktree.com/cron-in-docker
- https://stackoverflow.com/questions/42912755/how-to-create-a-db-for-mongodb-container-on-start-up
- https://blog.entirely.digital/docker-gunicorn-and-flask/