Ergast API - simple ETL in the Google Cloud
Introduction
As you might know from about section I am a huge Formula 1 fan. I love diving in statistics about historical seasons, drivers, or races. I have also noticed there are not enough good resources about that statistics on the internet. So I would like to perform a few projects using the Formula 1 data in the future. The very first step I have to do is collecting the data. The awesome source of the data is Ergast API. However, I would like to have the data in my own database. So I am going to create a simple ETL pipeline, which will extract the data from Ergast, modify it a bit and load it into the Google BigQuery after every race.
General architecture
ETL is a procedure that extracts, transforms, and loads data from multiple sources to a data warehouse or other target system. A lot of ETL tools are designed for processing large data. Using them for simple tasks might be overkill. I am going to keep my ETL as simple as possible. That’s how my ETL pipeline looks like:
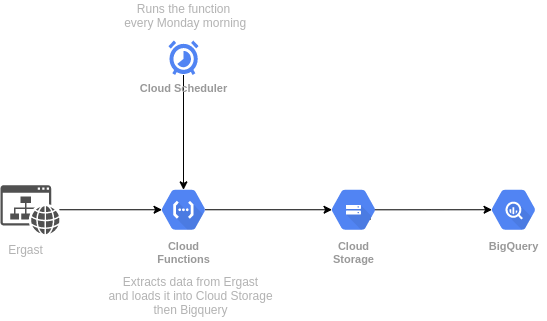
As you can see it is not so complicated. The main tool I am going to use is Cloud Functions - scalable pay-as-you-go functions as a service (FaaS) to run the code with zero server management. This tool is not so hard, requires just providing a code in one of the common programming languages, trigger type, memory allocated, and authentication or not. The function can be scheduled as a simple cron job in Cloud Scheduler. For me, it is the easiest way to set up a simple ETL in Google Cloud. I see just one disadvantage of this tool. The nature of Cloud Functions is the most abstract of serverless paradigms. That means it is impossible to run bash scripts because it assumes that the function is running in Unix like environment. It is possible to run bash scripts in the Cloud Run, but for my ELT I will use only Python. You would also wonder why the data is loaded into Cloud Storage first instead of loading it instantly to BigQuery. The answer is simple - loading to BigQuery directly from files is quite limited. Also, I do not consider storing that files as a bad thing. The last thing I would like to mention in that section is updating the database. The cron job will be scheduled to run a function every Monday morning - it’s after a race week. I am going to make a full load every week. The data is small (atm less < 10mb). For huge data, I would consider the delta approach probably, but I do not think it is needed here.
Requirements
Foreword I would like to stress that I am working directly from my project’s cloud shell. Everything can be also done from the local machine with Google Cloud SDK or just from UI.
The cloud function requires two files: main.py and requirements.txt. After setting up the directory, creating the virtual environment, and main.py file, let’s install the required packages and generate requirements.txt.
pip install pandas google-cloud-storage google-cloud-bigquery \
&& pip freeze > requirements.txt
The script needs also some built-in modules, the top of main.py file should look like this:
import urllib.request
import os
import zipfile
import re
import shutil
import pandas as pd
from google.cloud import storage
from google.cloud import bigquery
BigQuery’s dataset and storage bucket should be also created at the beginning.
bq --location=europe-central2 mk -d\
--description "The dataset with formula 1 data" \
f1_ds
gsutil mb -l EUROPE-CENTRAL2 gs://f1_bucket
To keep things easy dataset and bucket shall be in the same location.
Extract
Let’s name the function ergast_bq_etl. The start of is just setup of BigQuery and Google Storage. It is more related to load part, but I like too keep it at the top.
def ergast_bq_etl(request):
bq_client = bigquery.Client()
storage_client = storage.Client()
bucket = storage_client.bucket("f1_bucket")
Ergast gives three ways to extract the data. The first one is through API, for example using pyergast. The second one is through database images published by Ergast. The third one is just through csv files. The first way would be probably the most exciting, but I would like to keep things simple and also do not overuse the API. The second and third ways are quite similar because my approach to transfer data from MySql image to BigQuery would also assume converting the dumps to csv, so I can just skip it and use the third way. Everything in the extract part is to download zipped csvs using urllib.request, extract an archive using zipfile and save to a temporary directory.
# extract
url = "http://ergast.com/downloads/f1db_csv.zip"
# download zip to temporary directory
urllib.request.urlretrieve(url, "/tmp/f1db_csv.zip")
# unzip to temporary subirectory
with zipfile.ZipFile("/tmp/f1db_csv.zip", "r") as z:
z.extractall("/tmp/csv")
os.remove('/tmp/f1db_csv.zip')
Transform
The transform part is the quickest one. The results table has a lot of \N values in the INTEGER type columns. BigQuery can’t parse them, so I just simply replace them with blanks using Pandas.
# transform
# replace \N values in results.csv with blank, otherwise bigquery wont be able to parse it
df = pd.read_csv("/tmp/csv/results.csv")
df = df.replace("\\N", "")
df.to_csv("/tmp/csv/results.csv", index=False)
Load
Firstly, every csv file from the temporary directory needs to be loaded into Google Storage. It can be done via iterating temporary directory using os.listdir and upload_from_filename methods. At the end I remove tmp/csv using shutil.rmtree.
# storage load
# load csvs to google storage's bucket
for file in os.listdir("/tmp/csv"):
blob = bucket.blob(f"csv/{file}")
blob.upload_from_filename(f"/tmp/csv/{file}")
shutil.rmtree('/tmp/csv')
Now the files are ready to be transferred to BigQuery. The list_blobs method is really useful here, I can simply iterate over all files in the bucket and make a BigQuery table from each. Setting job config is the most important in this part. WRITE_TRUNCATE truncates table data and writes from the start, autodetect allows BigQuery to find the schema automatically, source_format is the format of data files.
# bigquery load
for csv in list(storage_client.list_blobs(bucket)):
table_id = f"project-123456.f1_ds.f1_{re.split('[/.]', csv.name)[1]}"
job_config = bigquery.job.LoadJobConfig(
write_disposition=bigquery.WriteDisposition.WRITE_TRUNCATE,
autodetect=True,
source_format=bigquery.SourceFormat.CSV,
)
uri = f"gs://f1_bucket/{csv.name}"
load_job = bq_client.load_table_from_uri(
uri, table_id, job_config=job_config)
load_job.result()
destination_table = bq_client.get_table(table_id)
return "OK"
Deploy and schedule
Now it is time to deploy the function to Cloud Functions. It can be done from the directory with main.py and requirements.txt by a simple command:
gcloud functions deploy f1_etl --region europe-central2 \
--entry-point ergast_bq_etl --runtime python39 --trigger-http
The function is already deployed, but there is still a need to schedule it. The function is HTTP targeted, so the trigger url is required. It can be found by using the following command:
gcloud functions describe f1_etl --region europe-central2
Now, let’s schedule the function using Cloud Scheduler. It’s just a simple cron job, the function will run every Monday morning. I also set up authentication, GET http method, and time zone.
gcloud scheduler jobs create http f1_cron --schedule "0 6 * * 1" --uri \
https://europe-central2-project-123456.cloudfunctions.net/f1_etl \
--oidc-service-account-email=name@project-123456.iam.gserviceaccount.com \
--http-method GET --time-zone "Europe/Warsaw"
Conclusion
I hope that showing a very simple approach to creating a small ETL in Google Cloud was interesting. To be honest I have already created a simple dashboard based on that BigQuery’s dataset. You can check it here. I would like to do more projects using F1 data in the future. Wish me luck!