Creating DE environment 3 - Dask distributed cluster
Introduction
Dask is a Python library for parallel computing. It is smaller and more lightweight than Spark (which is the most popular choice for distributed computing). Just because of this, it is an obvious pick for me. Dask is also Python native, so it is easier to integrate into the existing code, debug, understand, etc. If you know libraries like Pandas, Numpy, or Scikit-learn, you already know a big part of Dask. In this post I will build the distributed Dask cluster with 4 workers, using Docker and Ansible. It will be my computing engine for future projects.
Let’s get to work!
Docker stack
The Dask cluster will contain the following services:
- Distributed Dask scheduler: the midpoint between workers and clients. It is responsible for coordinating workers,
- 4 workers: two replicas for one data-worker-node, 1 thread, and 1GB of RAM for each. They are responsible for computations,
- Jupyter Notebook image: to use as a helper entry point and just for normal usage as a Jupyter server.
The docker-compose template for Dask can be found here. I will just change it a bit, I need to add the overlay network dask-network, constraints to choose the nodes to deploy services, set the resource limits for the worker nodes and I do not need to map the ports, exposing is enough because I use the Caddy’s reverse proxy. The scheduler and jupyter notebook services are also added to the caddy-network, because I will serve the jupyter lab and dask diagnostics tool. Workers has also environment variable that install external Python packages:
- prefect and prefect-dask for using the Prefect orchestration tool,
- s3fs for working with the files from the external S3 object storage - MinIO.
The complete docker-compose.yaml file looks like this:
# /composes/dask/docker-compose.yaml
version: "3.1"
services:
scheduler:
image: ghcr.io/dask/dask:latest
hostname: scheduler
expose:
- 8786
- 8787
deploy:
placement:
constraints:
- node.labels.role==master
networks:
- dask-network
- caddy-network
command: ["dask-scheduler"]
worker:
image: ghcr.io/dask/dask:latest
command: ["dask-worker", "tcp://scheduler:8786"]
environment:
EXTRA_PIP_PACKAGES: "prefect prefect-dask s3fs"
deploy:
placement:
constraints:
- node.labels.role==data-worker
replicas: 4
resources:
limits:
cpus: "0.50"
memory: 1G
networks:
- dask-network
notebook:
image: ghcr.io/dask/dask-notebook:latest
expose:
- 8888
environment:
- DASK_SCHEDULER_ADDRESS="tcp://scheduler:8786"
deploy:
placement:
constraints:
- node.labels.role==master
networks:
- dask-network
- caddy-network
networks:
dask-network:
name: dask-network
driver: overlay
caddy-network:
name: caddy-network
external: true
Deployment
The Ansible playbook for deploying my services is quite easy. The first thing to do is copy the docker-compose.yaml file from my remote host to the docker directory on my swarm manager instance, with reading and write permissions. The second task is deploying the services with the docker stack.
# swarm_deploy_dask.yaml
---
- hosts: data_master_nodes
tasks:
- name: Copy compose source template
template:
src: ./composes/dask/docker-compose.yaml
dest: /docker/dask/
mode: 0600
- name: Deploy dask
docker_stack:
state: present
name: dask
compose:
- /docker/dask/docker-compose.yaml
Run it with the standard command:
ansible-playbook swarm_deploy_dask.yaml -u charizard
Now from the master node success of the deployment can be checked with:
docker service ls
The output should look like this:
ID NAME MODE REPLICAS IMAGE PORTS
xasds38xdaer dask_notebook replicated 1/1 ghcr.io/dask/dask-notebook:latest *:8888->8888/tcp
pe342789dsf2 dask_scheduler replicated 1/1 ghcr.io/dask/dask:latest *:8786-8787->8786-8787/tcp
as1r78dxe24a dask_worker replicated 4/4 ghcr.io/dask/dask:latest
As you can see there are one notebook service, one scheduler service, and 4 workers services.
Now let’s add the entry to the Caddyfile. It shall contain Authelia’s forward_auth and reverse_proxy with the container name and port, like in the example from the previous post (that weird numbers after dask_notebook - I didn’t figure out how to change the name of the conteiner running in the swarm, I think it might be not possible).
notebook.brozen.best {
forward_auth authelia:9091 {
uri /api/verify?rd=https://whoareyou.brozen.best/
copy_headers Remote-User Remote-Groups Remote-Name Remote-Email
}
reverse_proxy dask_notebook.0.xd1234567:8888
Now the Jupyter notebook service is available on the standard HTTP/HTTPS ports.
The authentication token can be found in the service logs:
docker service logs dask_notebook
It is possible to set the login password also. The next thing to do is connect with the cluster requires the following code:
from dask.distributed import Client
client = Client("scheduler:8786")
Just type client in the next cell and execute it to obtain the information about the client, scheduler, and workers. In my case, the part of the output is:
Workers: 4
Total threads: 4
Total memory: 4.00 GiB
Pretty correct.
The Dask also offers the distributed diagnostics UI built with Bokeh that can be accessed on port 8787, which can be served similarly. The diagnostics service shows all detailed information about the cluster and running computations.
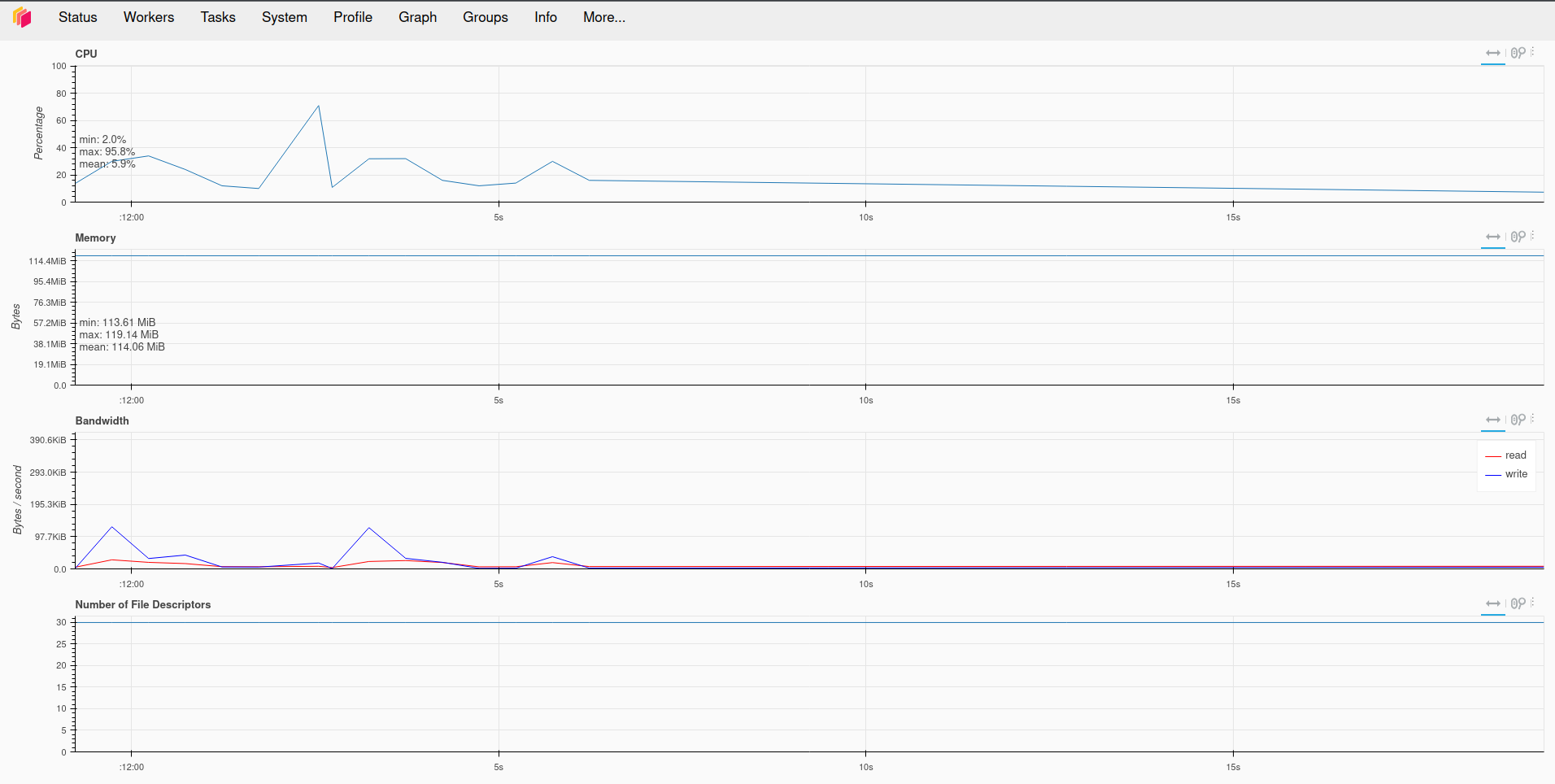
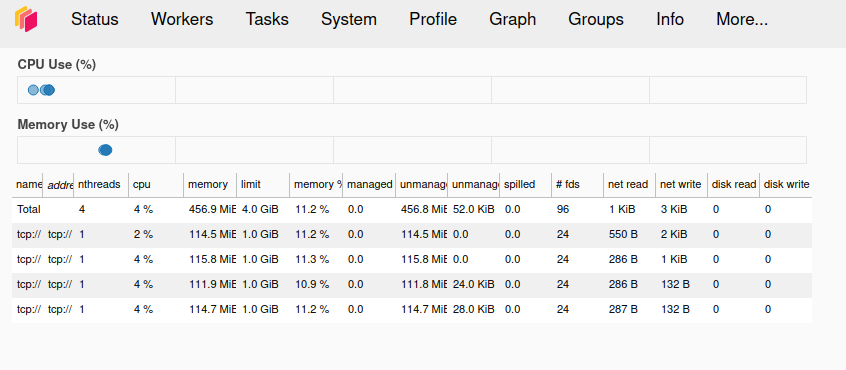
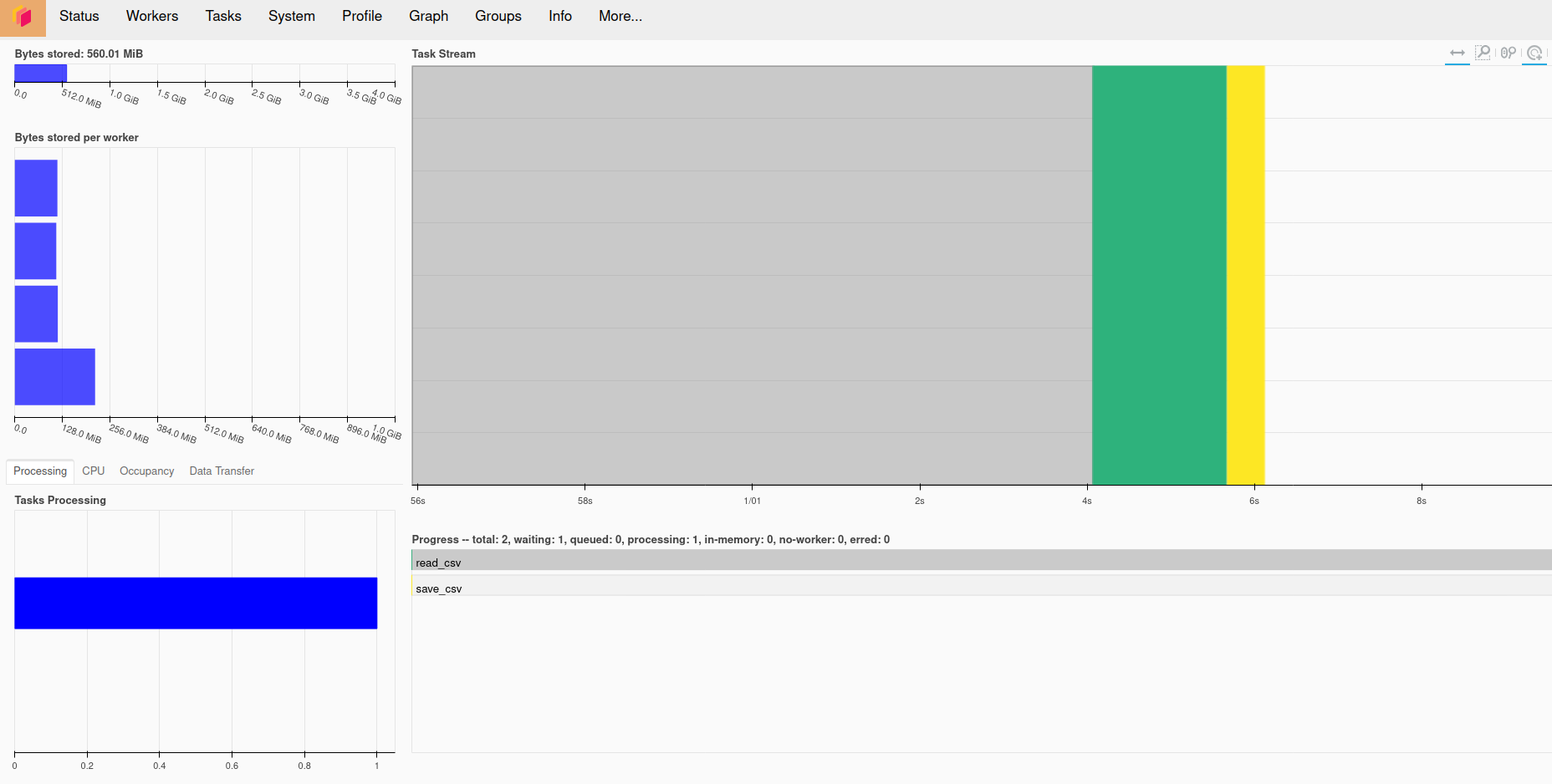
Conclusion
The task was not so hard, so the post was concise. I hope Dask will meet the expectations and choosing it over Spark was a good decision. The infrastructure already has the computing tool, so the next thing to do is configure the must-have databases. Cya in the next post from the series!